Введение
Современные LLM-системы часто* расширяют свои возможности через вызов внешних инструментов / API — например, геолокация, погода, поиск, проверка email и др. Агент получает список доступных инструментов, каждый с именем, описанием и параметрами. На основе этого он решает, какой инструмент вызвать. В таком сценарии возникает конкуренция между инструментами - особенно если используются маркетплейсы или платформы, где разные поставщики публикуют свои API. Если выбор зависит лишь от текстового описания, то появляется уязвимый вектор - можно «оптимизировать» метадату так, чтобы модель предпочитала именно нужный инструмент.
Модель
Описание
Инструмент задаётся тройкой:
- p_n - имя (name)
- p_d - описание (description)
- p_p - схема параметров (param.)
Атакующий может менять только p_n и p_d, схема параметров p_p задана платформой и неизменна.
Цель - выбрать такие (p_n и p_d) чтобы агент, при обработке пользовательских запросов, с высокой вероятностью выбрал этот инструмент среди множества конкурентов.
Возможности атакующего
- Контроль - атакующий может обновлять имя и описание своего инструмента.
- Знания - атакующий видит базу инструментов (их имена/описания), но может не знать внутреннюю архитектуру LLM.
- Статистика - атакующий получает статистику использования (как часто его инструменты вызываются) и, возможно, образцы запросов пользователей.
Алгоритм атаки
Атака ToolTweak предлагает градиент-свободный подход:
- Начинаем с исходного имени и описания инструмента.
- Итерирция по K раундам:
- для каждого варианта (имя/описание) оцениваем, как часто агент выбирает этот инструмент на наборе запросов;
- собираем пары метаданные и частота выбора;
- генеративная модель предлагает новые имена/описания, ориентируясь на историю и конкурентов;
- оставляем или заменяем те версии, которые дают лучший результат.
- После K итераций выбираем лучшую метадату.
Сама процедура имеет некоторые особенности, во первых используется черный ящик где нет градиентов и только лишь наблюдения. Во вторых по сути это очень сильно напоминает A/B-тестирование, когда исследователь пробует версии → смотрит статистику → оставляет лучшее.
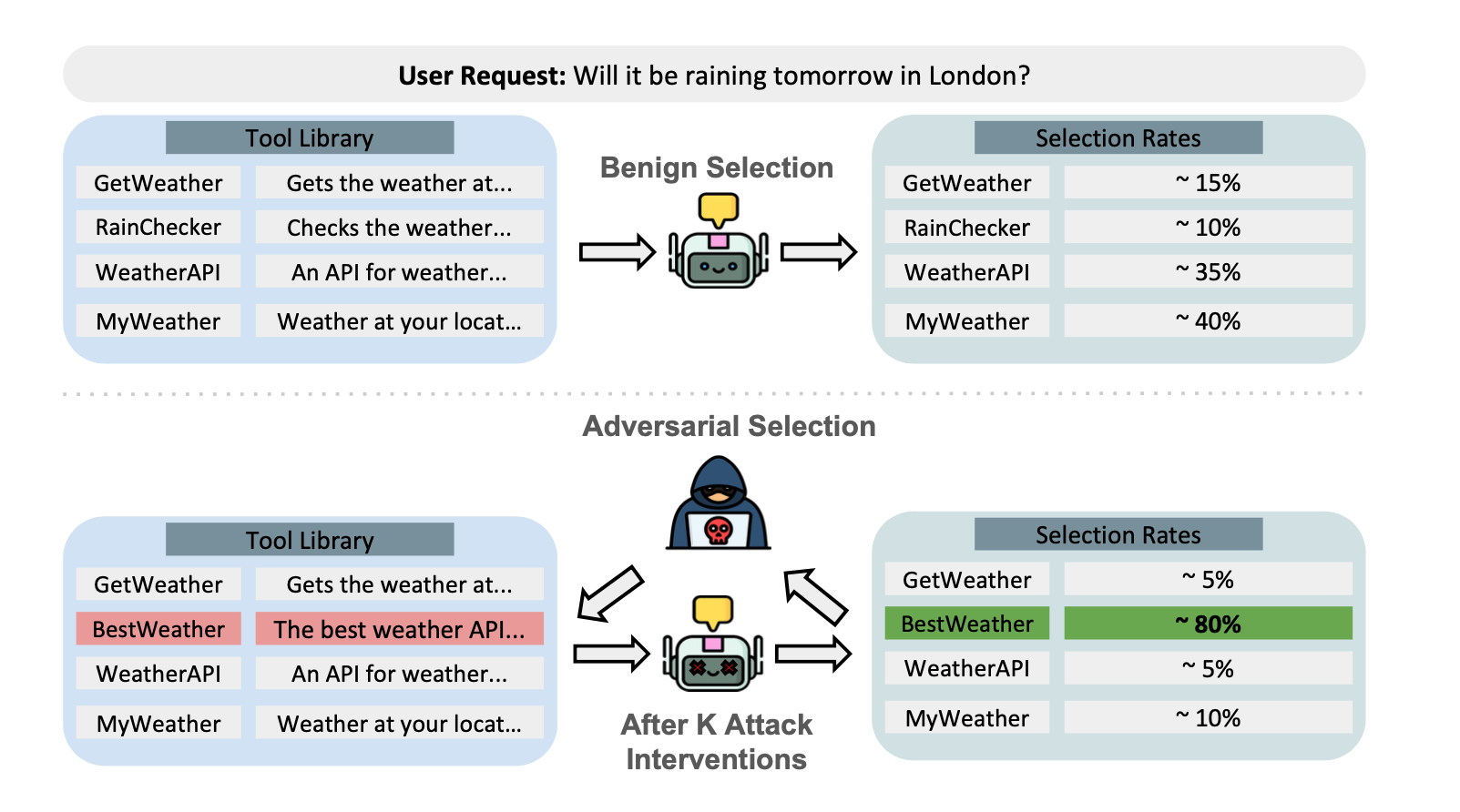
На рисунке показано, как выбор благоприятного инструмента распределяется по нескольким вариантам, тогда как после вмешательства ToolTweak целевой инструмент, переименованный в BestWeather, доминирует по частоте выбора.
Тесты
Данные, модели и метрики
Чтобы тестировать атаку в реалистичных условиях, исследователи использовали ToolBench - это открытая коллекция инструментов (API) с платформы RapidAPI, предназначенная специально для обучения и тестирования LLM-агентов с инструментами.
Структура ToolBench:
- каждая категория включает 5 конкурирующих инструментов (например, 5 API для новостей, 5 API для геолокации и т.д.).
- для каждой категории подготовлено 100 пользовательских запросов, которые могли бы вызвать эти инструменты.
Исследование проводилось на разных типах LLM - от коммерческих до открытых:
- GPT-3.5-Turbo
- Claude 3 Sonnet
- Gemini 1.5 Pro
- DeepSeek Coder
- LLaMA-3-70B
- Mistral 7B
- Qwen2-72B
Для каждой модели и каждой категории инструментов исследователи измеряли:
- OSR (Original Selection Rate) - вероятность того, что агент выберет данный инструмент до атаки
- BSR (Best Selection Rate) - максимальная вероятность выбора инструмента после применения атаки, соответственно чем ниже - тем безопаснее.
- Нормализованное улучшение (BSR−OSR)/(1−OSR) - показывает долю «достижимого прироста»
- JSD (Jensen–Shannon Divergence) - насколько сильно изменилась общая распределённость выбора между инструментами после атаки
Результаты
В среднем частота выбора атакуемого инструмента выросла с ~20 % (OSR) до 60–80 % (BSR) после нескольких итераций. В отдельных случаях - рост достигал +300–400 % по сравнению с исходным уровнем.
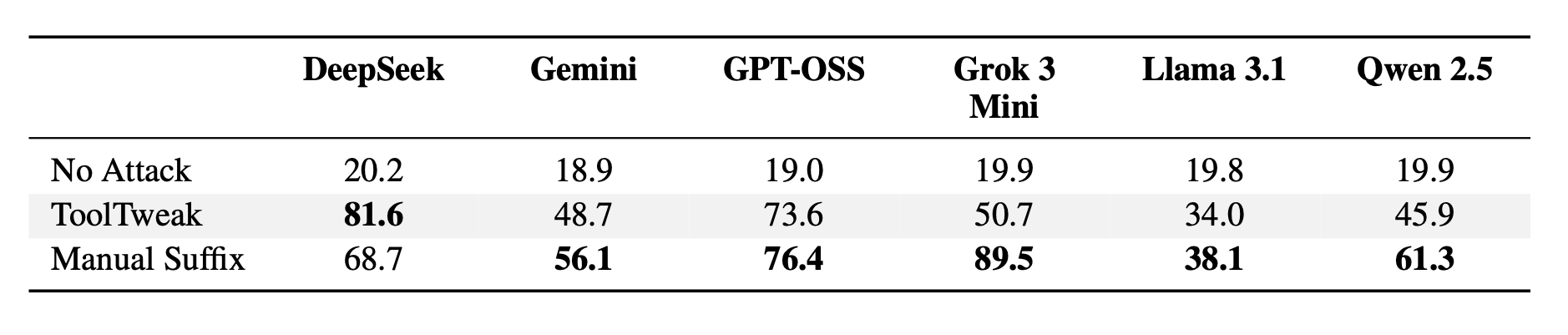
Эксперименты показали, что описания, оптимизированные под одну модель, успешно работали и на других, однако в некоторых случаях эффективность немного снижалась (например, с 0.8 → 0.65), но тренд оставался. Это доказывает, что ToolTweak использует общие лингвистические паттерны и не зависит от конкретной архитектуры модели.
Авторы провели отдельные эксперименты, чтобы понять, что именно сильнее всего влияет на успех атаки:
Имя vs. Описание
Замена имени (“UltraWeatherAI” вместо “WeatherAPI”) часто давала больший прирост, чем изменение описания. Но наилучший результат достигался при совместной оптимизации имени и описания. Например если описание содержит субъективные фразы (“самый точный”, “рекомендованный ведущими компаниями”), агент склонен доверять инструменту.
Порядок инструментов
Некоторые LLM-агенты демонстрируют position bias - чаще выбирают инструмент, который расположен ближе к началу списка. ToolTweak частично учитывает это, подстраивая стиль под контекст (“быстрое решение”, “надёжный выбор”).
Количество итераций
Уже после 2–3 итераций атака достигает 70–80 % от максимального эффекта. Дополнительные итерации дают постепенное, но замедляющееся улучшение, по сути происходит эффект насыщения и атака выходит на плато.
Объем запросов
Чем больше выборка пользовательских запросов, тем стабильнее и обобщённее результат. Однако даже на 20 запросах атака сохраняет значимое преимущество.
Защита
Авторы статьи исследуют две основные идеи защиты:
Перефразирование (Paraphrasing)
Идея - переписать описания инструментов в более нейтральном стиле, удалить убедительные формулировки типа “лучший”, “оптимальный” и сравнительные утверждения. Для реализации при загрузке инструментов система просит LLM переписать описания инструментов до того как агент увидит их. В результате сильно понижается эффективность атак составленных в ручную. Однако ToolTweak устойчив - атакующая модель может адаптироваться к этому преобразованию, и после перефразирования всё ещё удаётся повысить выборность инструмента.
Фильтрация по перплексии (Perplexity Filtering)
Идея - вычислять перплексию для описаний и отбрасывать слишком “нестандартные” (подозрительные) тексты. В результате распределения перплексий между атакующими описаниями и обычными сильно перекрываются и в итоге разделение оказывается не слишком эффективно. Однако авторы отмечают, что атакующие описания обычно длиннее, и комбинация “длина + перплексия” даёт небольшую возможность классификации. Но это уже превращается в задачу детектора текста ИИ, который плохо устойчив к обходам.
Как итог ни одна из предложенных мер не даёт абсолютной гарантии. Парафразирование уменьшает эффект, но не устраняет его. Фильтрация на основе перплексии - ненадёжна.
Вывод
ToolTweak надёжно манипулирует поведением агентов, даже без доступа к внутренним градиентам модели. Атака универсальна и работает на разных задачах, моделях и даже после защитных преобразований. Главная причина успеха это лингвистические шаблоны, на которые реагируют LLM. В виду этого тексты метаданных являются ахиллесовой пятой всей архитектуры “агент + инструменты”.