Введение
Статья описывает метод RLSpoofer - атаку на водяные знаки в текстах LLM. Водяные знаки используется для определения, был ли текст сгенерирован моделью или нет. Авторы показывают, что его можно подделать даже без доступа к внутренностям системы. Основная идея заключается в том что атака рассматривает водяные знаки не как конкретный сигнал, а как распределение вероятностей токенов. В данном случае цель - сдвинуть распределение генерации так, чтобы текст выглядел как помеченный водяным знаком (watermarked).
Ключевые концепции
Модель угроз
В этой работе рассматривается реалистичный сценарий атаки, где у атакующего почти нет привилегий.
Атакующий не знает:
- секретный ключ водянного знака (как именно он вставляется);
- как работает детектор;
- какой порог используется для определения текста сгенерированного моделью.
Атакующий может:
- отправлять тексты в модель с водяным знаком;
- получать на выходе тексты помеченные водяным знаком;
- собирать пары вида - обычный текст (human-like) + перефразированный текст сгенерированный моделью (watermarked)
Задача атакующего сгенерировать текст, который:
- Сохраняет смысл оригинала, чтобы не было заметно подмены
- Определяется как watermarked чтобы обмануть детектор
Аатака не пытается вставить конкретные “магические” токены, а вместо этого она работает на уровне вероятностей слов - распределений. То есть:
- существует распределение “как пишет человек” следовательно это human-like;
- существует распределение “как пишет модель” следовательно это watermarked.
Важно отметить, что и human-like и watermarked - это две модели. Одна копирует стиль другой путём отдаления от human-like и приближаясь к watermarked. То есть модель учится писать “как watermarked модель”, даже не зная, что такое watermark.
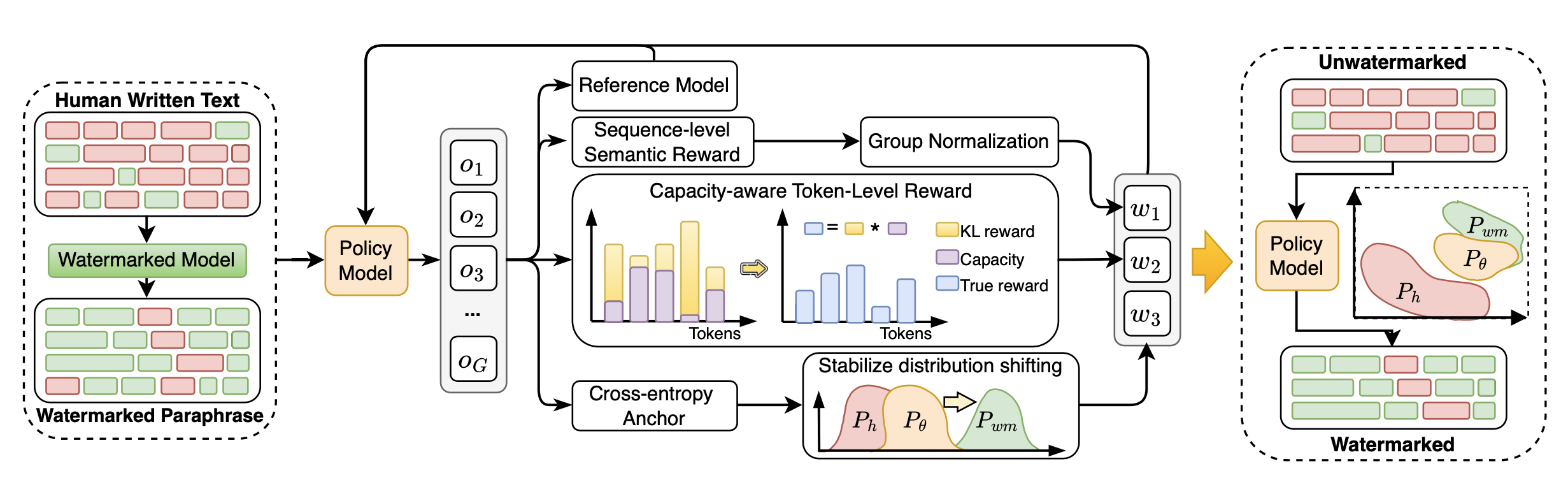
Архитектура RLSpoofer
Используются около 100 пар - обычный текст + перефразированная watermarked версия.
RL модель обучается через reward в несколько шагов:
Token-level reward - насколько токен похож на watermark распределение
Capacity-aware weighting - ограничение, чтобы не ломать смысл, что бы понимать где можно менять токены, а где нельзя
Semantic reward - контролирует сохранение смысла, модель сравнивает свой текст с оригиналом и watermarked версией
Cross-entropy anchor - стабилизирует обучение путём ограничения в рамках нормального языка
Алгоритм атаки:
- Генерируется перефраз текста
- Считается reward:
- близость к watermark
- сохранение смысла
- Модель обновляется
- Повтор
Эксперименты
Главная метрика — Spoof Success Rate (SSR), которая отвечает на вопрос сколько процентов текстов одновременно сохраняют смысл и определяются как watermarked.
Из 100 сэмплов 62 были валидированы как watermarked, хотя изначально ими не были. Интересно отметить, что эксперименты ставилились всего на 100 примерах, а это очень мало, однако объяснимо, так как модель уже знает язык и ей нужно только понять распределени для текста с водяным знаком.
В качестве сравнения эксперименты проводились с использованием базовых методов - distillation, DITTO и DPO. Однако они решают задачу косвенно и поэтому требуют значительно больше данных - примерно оконо 10000 сэмплов.
В случае с distillation атакующая модель обучается воспроизводить выходы watermarked модели. Она получает пары «вход — watermarked перефраз» и пытается максимально точно их предсказывать. Однако такой подход не ориентирован на саму цель. Модель просто копирует поведение, не понимая, какие именно изменения приводят к появлению watermark-сигнала. В результате требуется большое количество примеров, чтобы статистически уловить этот скрытый паттерн.
DITTO расширяет идею distillation, добавляя анализ распределения токенов. После обучения модель пытается воспроизвести статистические особенности watermarked текста, например, частоты определённых токенов. Тем не менее, этот подход также работает на уровне усреднённой статистики и не учитывает контекст и семантические ограничения. Он не различает, где изменения допустимы, а где приведут к искажению смысла, поэтому эффективность остаётся ограниченной, несмотря на большие объёмы данных.
DPO использует другой подход — обучение на предпочтениях. Модель получает пары текстов, где один вариант считается «лучше» (watermarked), а другой — «хуже» (обычный), и учится отдавать предпочтение первому. Однако такой сигнал слишком общий. Он не указывает, какие именно изменения нужно внести в текст, чтобы достичь нужного эффекта. В результате модель понимает направление, но не получает точного механизма его реализации.
| Model | Method | EWD SSR | EWD P-SP | SWEET SSR | SWEET P-SP | KGW SSR | KGW P-SP | Unigram SSR | Unigram P-SP | PF SSR | PF P-SP | PMark SSR | PMark P-SP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Qwen3-0.6B | Distill | 42.3 | 0.75 | 20.0 | 0.76 | 35.8 | 0.68 | 13.8 | 0.84 | 6.50 | 0.97 | 20.0 | 0.90 |
| Qwen3-0.6B | DITTO | 7.50 | 0.43 | 6.75 | 0.41 | 1.00 | 0.33 | 0.25 | 0.32 | 5.50 | 0.79 | 11.8 | 0.63 |
| Qwen3-0.6B | DPO | 0.25 | 0.57 | 0.00 | 0.76 | 1.00 | 0.66 | 0.25 | 0.32 | 2.50 | 0.57 | 6.25 | 0.63 |
| Qwen3-0.6B | RLSpoofer | 54.3 | 0.73 | 50.5 | 0.79 | 52.0 | 0.72 | 49.5 | 0.70 | 33.3 | 0.66 | 29.5 | 0.92 |
| Qwen3-1.7B | Distill | 43.8 | 0.80 | 26.8 | 0.79 | 44.5 | 0.75 | 19.5 | 0.81 | 7.00 | 0.96 | 20.3 | 0.90 |
| Qwen3-1.7B | DITTO | 21.5 | 0.53 | 29.0 | 0.56 | 13.8 | 0.52 | 1.50 | 0.36 | 7.50 | 0.86 | 16.5 | 0.68 |
| Qwen3-1.7B | DPO | 0.25 | 0.94 | 0.00 | 0.84 | 1.00 | 0.96 | 0.50 | 0.87 | 4.25 | 0.58 | 22.5 | 0.93 |
| Qwen3-1.7B | RLSpoofer | 53.5 | 0.76 | 52.0 | 0.71 | 52.0 | 0.71 | 54.8 | 0.73 | 29.0 | 0.73 | 29.5 | 0.90 |
| Qwen3-4B | Distill | 51.3 | 0.81 | 37.3 | 0.82 | 57.0 | 0.79 | 28.0 | 0.80 | 6.00 | 0.96 | 21.5 | 0.92 |
| Qwen3-4B | DITTO | 56.0 | 0.68 | 43.3 | 0.66 | 36.5 | 0.61 | 2.25 | 0.39 | 3.50 | 0.88 | 16.5 | 0.71 |
| Qwen3-4B | DPO | 0.25 | 0.78 | 0.00 | 0.78 | 1.00 | 0.93 | 0.75 | 0.59 | 5.25 | 0.88 | 17.5 | 0.68 |
| Qwen3-4B | RLSpoofer | 56.5 | 0.73 | 52.3 | 0.75 | 58.0 | 0.75 | 54.8 | 0.74 | 62.0 | 0.77 | 36.3 | 0.91 |
| Qwen2.5-3B-Instruct | Distill | 55.5 | 0.76 | 49.8 | 0.77 | 60.3 | 0.74 | 25.8 | 0.80 | 6.50 | 0.93 | 22.3 | 0.91 |
| Qwen2.5-3B-Instruct | DITTO | 14.0 | 0.50 | 22.3 | 0.54 | 9.50 | 0.48 | 0.25 | 0.34 | 5.25 | 0.72 | 11.3 | 0.56 |
| Qwen2.5-3B-Instruct | DPO | 0.00 | 0.88 | 0.00 | 0.87 | 1.25 | 0.87 | 2.50 | 0.78 | 6.25 | 0.83 | 24.3 | 0.95 |
| Qwen2.5-3B-Instruct | RLSpoofer | 53.5 | 0.70 | 54.5 | 0.75 | 57.3 | 0.72 | 54.5 | 0.77 | 50.3 | 0.68 | 30.3 | 0.89 |
| Llama3.2-3B-Instruct | Distill | 53.8 | 0.77 | 45.5 | 0.76 | 56.3 | 0.75 | 26.0 | 0.77 | 8.75 | 0.93 | 23.3 | 0.89 |
| Llama3.2-3B-Instruct | DITTO | 19.3 | 0.54 | 24.3 | 0.56 | 14.0 | 0.51 | 1.00 | 0.35 | 6.50 | 0.79 | 18.0 | 0.65 |
| Llama3.2-3B-Instruct | DPO | 2.50 | 0.49 | 0.50 | 0.53 | 0.75 | 0.36 | 7.75 | 0.60 | 6.25 | 0.67 | 25.0 | 0.87 |
| Llama3.2-3B-Instruct | RLSpoofer | 54.5 | 0.70 | 54.5 | 0.74 | 55.3 | 0.76 | 52.0 | 0.72 | 49.8 | 0.85 | 33.3 | 0.92 |
Вывод
В статье показано, что современные подходы к watermarking в LLM не обеспечивают надёжной защиты от подделки. Даже в чёрном ящике, без доступа к ключу или детектору, атакующий может воспроизвести статистические свойства текста с водяными знаками и заставить модель генерировать выходы, которые проходят проверку.
Предложенный метод RLSpoofer демонстрирует, что задача может решаться напрямую через оптимизацию распределения генерации с учётом семантики и ограничений на изменения. За счёт этого удаётся добиться высокой эффективности при минимальном объёме данных, что резко снижает стоимость и сложность её реализации.
Ключевой вывод заключается в том, что watermark в текущем виде является не устойчивой защитой, а лишь слабым статистическим сигналом, который может быть воспроизведён другой моделью. Это ставит под сомнение применимость такого подхода как надёжного механизма детекции AI-контента и указывает на необходимость разработки более устойчивых методов защиты.