Ссылка на оригинал
Ссылка на GitHub
Введение
MCPThreatHive — это попытка систематизировать безопасность экосистем Model Context Protocol (MCP), превратив её из набора отдельных инструментов в полноценный пайплан для поиска уязвимостей. В отличие от классических инструментов, система ориентирована не на точечную проверку MCP-серверов, а на непрерывный сбор информации об угрозах, их автоматическую классификацию и построение связей между ними. Основная идея — рассматривать безопасность MCP как динамическую среду, где угрозы постоянно появляются, комбинируются между собой и требуют анализа на уровне всей экосистемы, а не отдельных компонентов.
Документ выделяет три фундаментальных ограничения существующих решений по безопасности MCP:
Не учитывается моделирование композиционных атак Атаки возникают не из одного инструмента, а из их комбинации.
Отсутствие постоянного сканирования на уязвимости
Большая часть инструментов функционирует в режиме разового анализа на конкретный момент времени.Отсутствие единой классификации
Используются отдельные фреймворки, но нет унифицированного слоя.
MCPThreatHive позиционируется как система, закрывающая все три пробела одновременно.
Архитектура
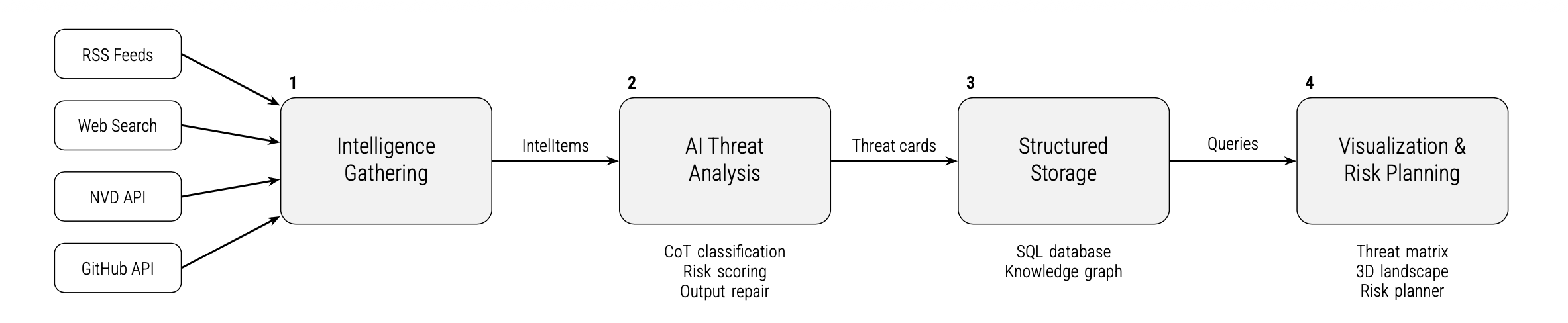
Система построена как 4-этапный pipeline:
Intelligence Gathering
Сбор данных из:- RSS (ArXiv, security блоги)
- NVD
- GitHub
- Web
AI Threat Analysis
LLM:- классифицирует угрозы (MCP-38)
- сопоставляет с STRIDE и OWASP
- оценивает риск
Structured Storage
- SQL база
- Граф знаний (Neo4j)
Visualization & Risk Planning
- Матрица угроз
- 3D визуализация
- Планирование рисков
Фактически эта архитектура отражает переход от сканера к аналитической платформе, а сам документ выделяет ключевую особенность MCP - атака происходит не на уровне кода, а на уровне семантики.
Также выделяются основные классы атак:
- Indirect Prompt Injection
- Tool Description Poisoning
- Parasitic Tool Chains
- Preference Manipulation
- Dynamic Mutation
Ключевая идея в том что LLM принимает решения на основе текста следовательно любой текст становится может быть атакой.
MCP-38
Одно из главных преимуществ системы это использование MCP-38 taxonomy, а конкретно модели “MCP-17” (parasitic tool chains):
Атака разбивается на этапы:
- Ingestion (внедрение инструкции)
- Collection (сбор данных)
- Disclosure (эксфильтрация)
Это позволяет анализировать цепочки инструментов, а не отдельные вызовы, что является критичным для агентной системы.
Knowledge Graph
Вместо классических таблиц используется граф:
Node types:
- Threat
- Tool
- CVE
- Mitigation
- Intelligence Item
Edge types:
- EXPLOITS
- CHAINS_INTO
- MITIGATED_BY
Это позволяет находить атаки в несколько шагов, анализировать зависимости и строить цепочку атак, что в полне оправдывает графовый подход.
Scoring
Для подсчёта “веса” атаки используются:
- Считаются факторы:
- Impact
- Success rate
- Persistence
- Ease of exploitation
Вводятся MCP-specific множители:
- semantic attacks
- multi-tool chains
- low observability
Выаодится финальный результат от 0 до 10:
- Low
- Medium
- High
- Critical
Ограничения
Документ явно признаёт слабые стороны: - галлюцинации - ошибки классификации - нестабильность - требуется большой выходной бюджет (около 12к токенов) - проблемы с нестандартными источниками - многоязычные данные - агрессивные описания могут считаться атаками
Итог
MCPThreatHive — это сильный концептуальный шаг в сторону систематизации MCP-угроз и анализа композиционных атак. Переход к графоцентричной модели безопасности даёт явное преимущество для построения многокомпонентных атак. Также стоит отметить развитие и использование собственной модели угроз — MCP-38, что создаёт задел для глубокого и долгосрочного изучения данного направления.
Однако ранняя стадия репозитория и высокая зависимость от LLM вносят свои коррективы и вряд ли позволят в текущем состоянии выйти на уровень рантаймового механизма защиты или полноценного продуктового решения.
Проект отлично подходит для исследовательских команд, архитекторов безопасности и задач моделирования угроз. На практике его стоит использовать как инструмент аудита поверх существующих решений.