Введение
В рамках программы DARPA AI Cyber Challenge (AIxCC) команда исследователей из Texas A&M University, City University of Hong Kong и Imperial College London разработала систему FuzzingBrain — полностью автоматизированную платформу, использующую большие языковые модели (LLM) для поиска и исправления уязвимостей в реальных проектах на C и Java.
Ссылка на хранилище проекта на GitHub
Архитектура FuzzingBrain
Система состоит из четырёх взаимосвязанных компонентов:
- CRS WebService — координирует задания, строит тестовые окружения.
- Static Analysis Service — выполняет статический анализ кода.
- Worker Services — запускают fuzzing и LLM модули для генерации тестов и патчей.
- Submission Service — отправляет результаты и устраняет дубликаты.
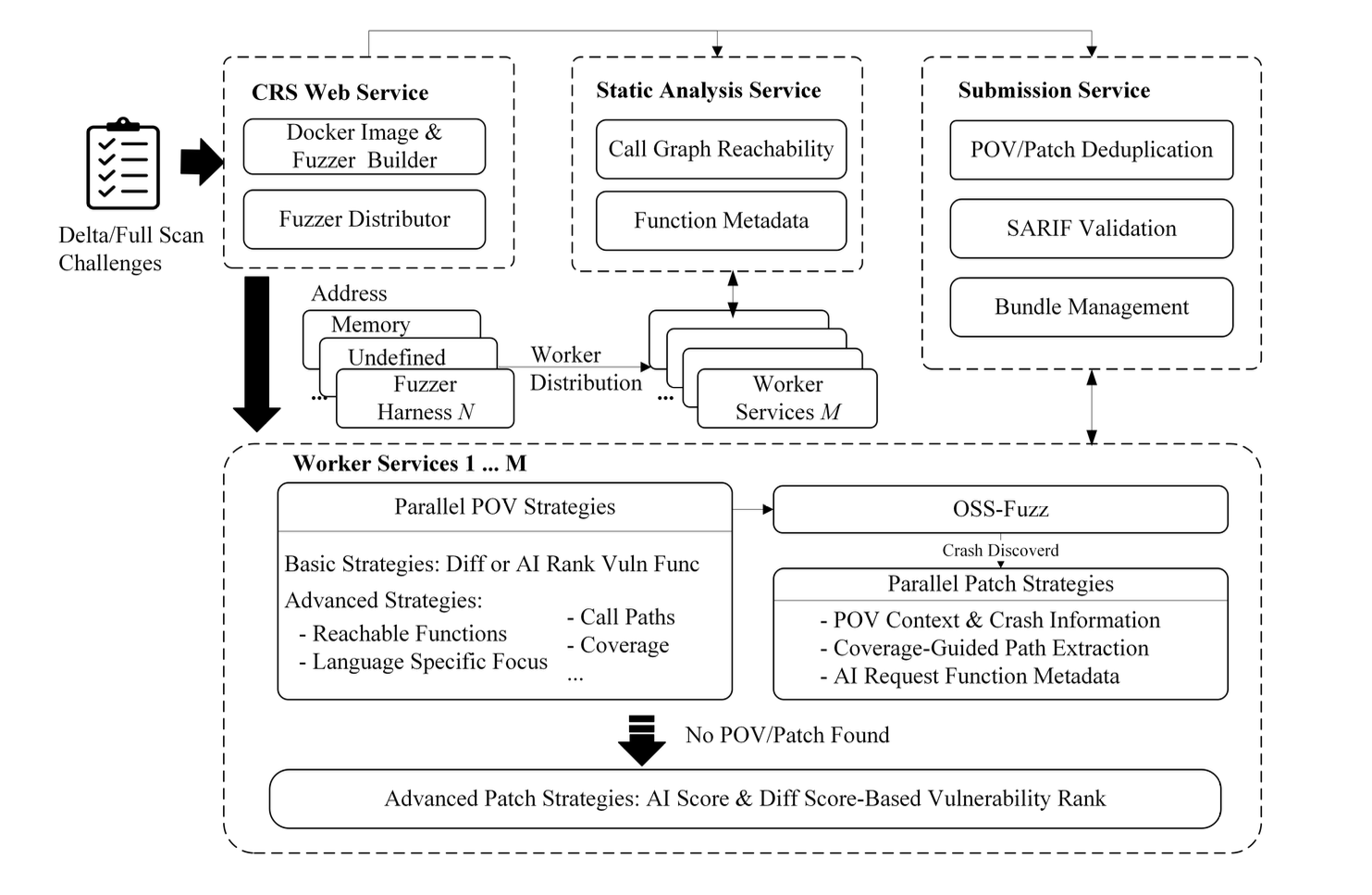
Стратегии исследования
Фаззинг
Главная задача фаззинга - подобрать данные для Proofs-of-Vulnerability
Система сочетает в себе два подхода:
- Традиционный фаззинг c использованием libFuzzer
- LLM-подход, в котором модели (GPT-4o, Claude, Gemini и др.) анализируют код, создают тесты, изучают ошибки и итеративно улучшают входные данные.
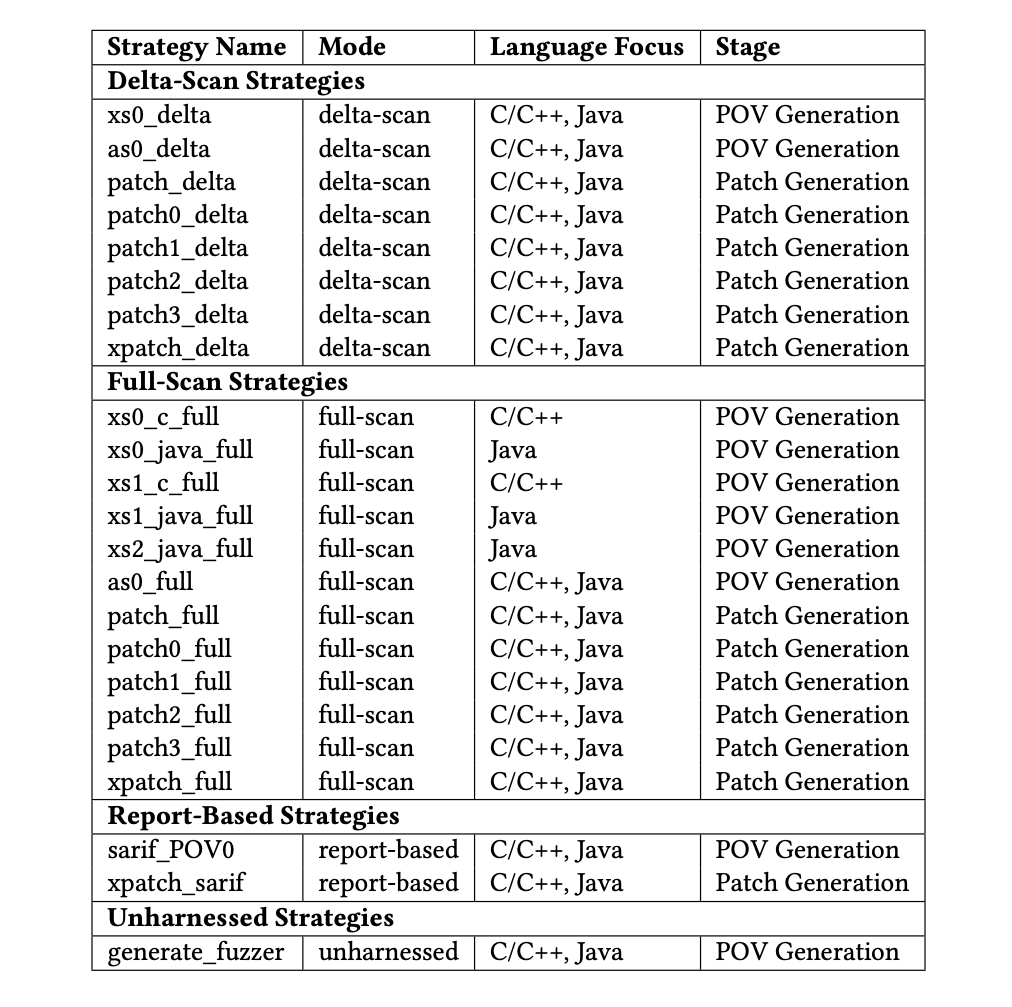
В общей сложности реализовано 10 стратегий фазинга:
- две разработаны для дельта-сканирования (анализ изменений в конкретном коммите)
- шесть для полного сканирования (анализа всей кодовой базы целиком, без ограничений на конкретный коммит.)
- одна для задач на основе отчетов (анализ внешних отчётов статического анализа в формате SARIF (Static Analysis Results Interchange Format))
- одна для неиспользуемых задач (анализ когда в проекте отсутствует специальная тест-оболочка, через которую передаются входные данные)
Патчинг
После выявления уязвимости система переходит к её исправлению. Патчи создаются в формате .diff и проходят валидацию по четырём критериям:
- Применимость к коду.
- Успешная компиляция.
- Устранение ошибки (POV больше не воспроизводится).
- Сохранение функциональности.
Подходы для патчинга:
- patch_delta / patch_full
- LLM получает diff коммита + crash-лог.
- Определяет функции, которые могли вызвать ошибку.
- Генерирует исправленную версию функции и diff-файл.
- Использует итеративную схему с обратной связью (ошибки сборки, POV, тесты).
- patch0_delta / patch0_ful
- Считает, что все функции, изменённые в коммите, потенциально уязвимы.
- Пропускает фазу LLM-анализа для определения цели
- Автоматически применяет патч ко всем изменённым функциям
- patch1_delta / patch1_full
- Комбинирует анализ diff’а и результаты LLM-идентификации функций
- Формирует объединённое множество кандидатов
- patch2_delta / patch2_full
- Использует динамический анализ потока управления
- При неудачных патчах собирает данные о выполненных ветвях и передаёт их LLM в следующем промпте
- patch3_delta / patch3_full
- Добавляет к стандартному процессу знания из экспертных шаблонов и примеров
- Использует анализ уязвимости из этапа POV
- Использует каталог примерных исправлений, отсортированных по типу уязвимости
- Использует возможность запроса дополнительного контекста
- XPatch
- Активируется, если за половину времени задачи POV не найден
- Патч генерируется без подтверждения ошибки
- LLM оценивает все функции по шкале 1–10 и выбирает top-k
SARIF Анализ
FuzzingBrain рассматривает SARIF-отчёты как дополнительный источник знаний о коде. Для этого реализован SARIF Analysis Service в составе Static Analysis Service.
Весь процесс состоит из пяти этапов:
- Получение SARIF-отчета, содержащего множество записей, из * внешнего анализатора (например, CodeQL или другого * SAST-инструмента).
- SARIF-парсер извлекает необзодимые данные (имя функции, путь к * файлу, строку/позицию, тип CWE, текст описания проблемы, * call-trace, если он есть)
- LLM верефицирует запись SARIF и решает, настоящая ли это * уязвимость (true positive) или ложная тревога (false positive) * путём анализа контекста кода и сообщение анализатора.
- Сохранение подтверждённых (true positive) отчёты в базе и * создание задания для следующего этапа (LLM-based POV generation * или LLM-based patching)
- Передача контекста в фаззинг / патчинг:
- Для POV LLM получает SARIF-данные как часть промпта, чтобы сфокусироваться на конкретной функции и типе уязвимости.
- Для патча SARIF помогает LLM выбрать правильную цель и тип исправления.
Результат
Всего разработано 23 стратегии из них 10 для создания POV и 13 для патчинга.
FuzzingBrain был развёрнут на кластерной инфраструктуре, предоставленной для участников соревнования DARPA AI Cyber Challenge (AIxCC), где у команды было примерно около 100 виртуальных машин. В соревновании команды получали задачи , каждая из которых включала:
- Исходный код на C/C++ или Java
- Специальные точки входа для фаззинга
- Сommit diff для Delta-Scan задач
- SARIF-отчёты для Report-Based задач.
В результате использования системы обнаружены 28 уязвимостей, включая 6 нулевых дней, и 14 успешно исправленных.
Выводы
FuzzingBrain реализует полный цикл автоматического поиска и исправления уязвимостей, где LLM анализирует причины сбоя, подбирает конкретную уязвимую функцию, создает корректирующий diff, проверяет его на уровне компиляции, безопасности и функциональности.
Вероятнее всего такой подход превращают LLM из рекомендательной системы в кибер-исследовательский комплекс, способный выполнять сложные задачи по анализу программного кода без участия человека.