Введение
Стремительное развитие больших языковых и мультимодальных моделей превратило безопасность из второстепенной задачи в критический приоритет наравне с производительностью. Однако существующие инструменты оценки безопасности до сих пор остаются фрагментированными, так как оценка поведения моделей и диагностика их внутренних механизмов существуют изолированно друг от друга.
Чтобы решить эту проблему, исследователи из Шанхайской лаборатория искусственного интеллекта (Shanghai Artificial Intelligence Laboratory) представили проект с открытым исходным кодом под названием DeepSight.
Архитектура
DeepSight предлагает единую парадигму «оценка-диагностика», реализованную через два ключевых компонента:
DeepSafe - оценка модели
Это модульный фреймворк, объединяющий большое количество бенчмарков безопасности, включая SALAD-Bench и HarmBench. Он автоматизирует процесс от инференса модели до генерации отчетов. Важной особенностью является использование ProGuard — специализированной модели-судьи, обученной на 87 тысячах пар данных для выявления тонких рисков, которые пропускают обычные оценщики.
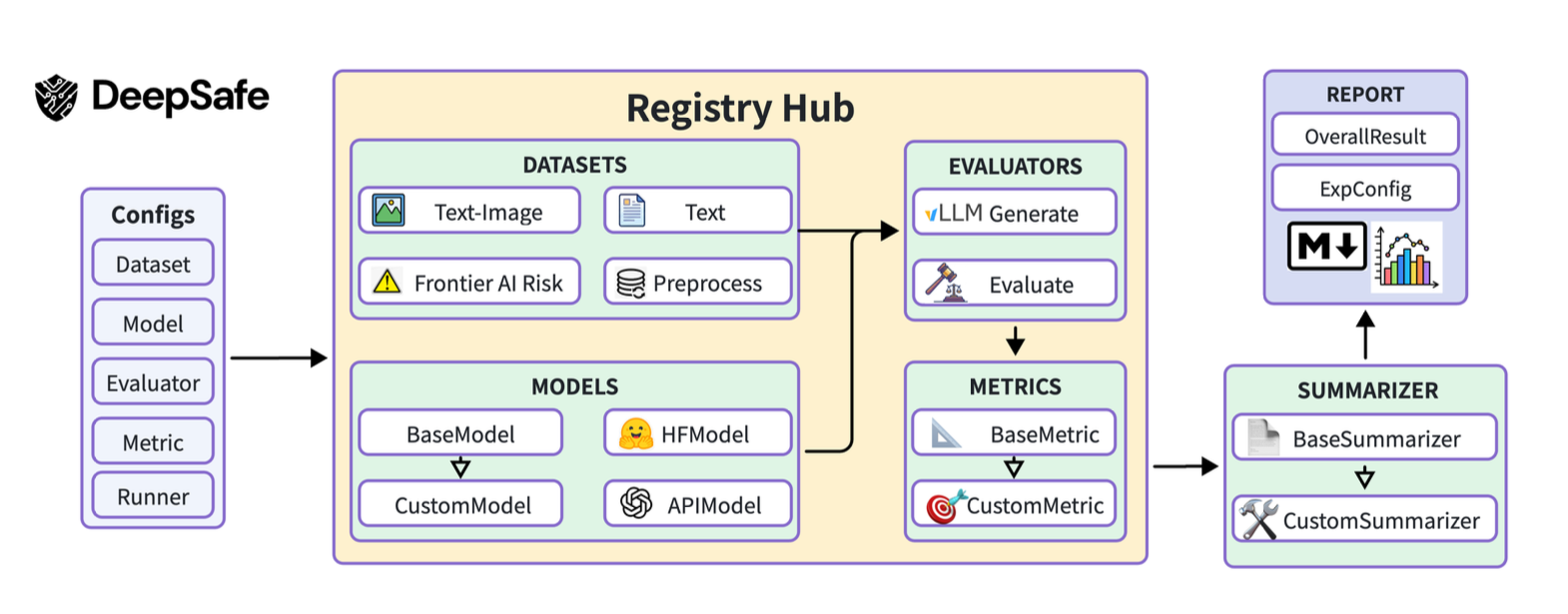
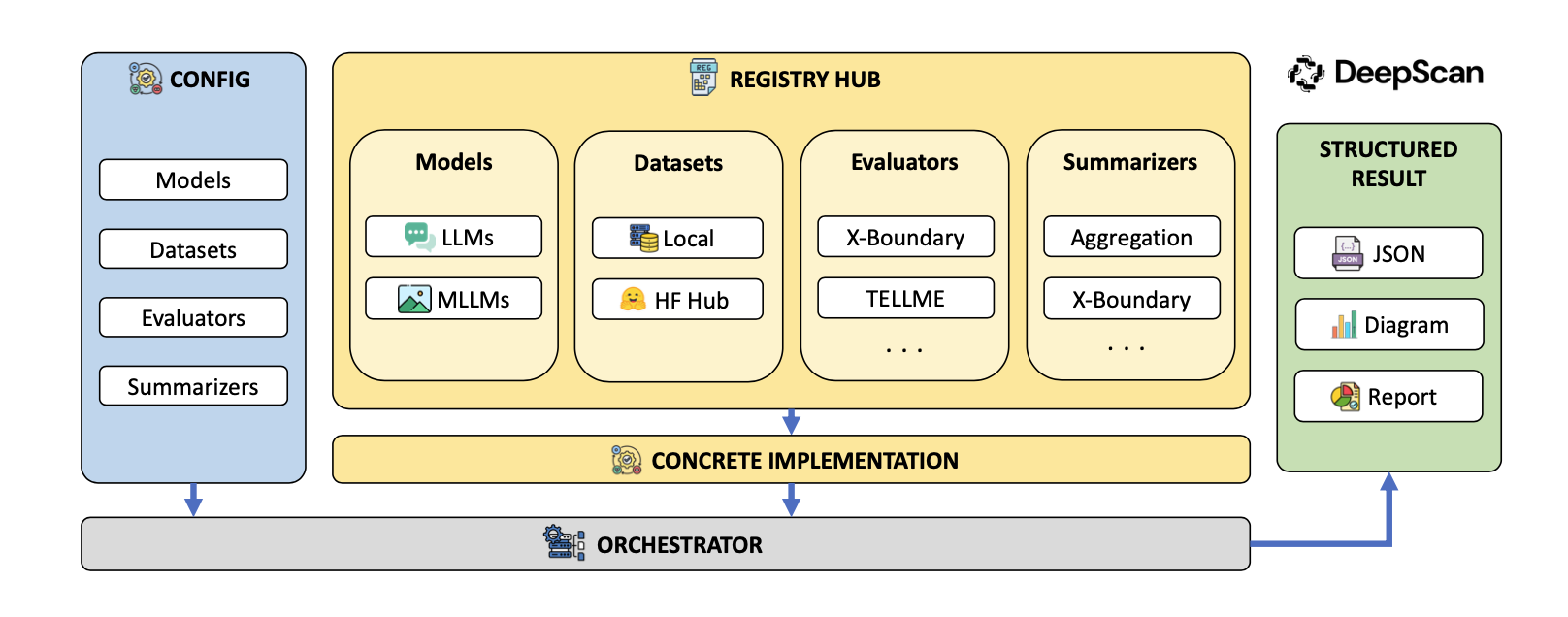
DeepScan - внутренняя диагностика
Это инструмент для анализа «белого ящика». Он исследует промежуточные активации слоев и нейронов без изменения весов модели. DeepScan использует такие методы как:
- X-Boundary - анализ геометрии скрытого пространства;
- TELLME - измерение разделения представлений;
- SPIN - анализ конфликтов целей, например, приватности и честности.
Эксперименты
В рамках презентации DeepSight авторы провели масштабное исследование 14 передовых моделей, которое выявило несколько критических трендов в ландшафте безопасности ИИ на начало 2026 года. В список исследуемых моделей попали:
- GPT-4o;
- Claude 3.5 Sonnet;
- Qwen2.5;
- Gemini-3.
Эксперименты проводились в трех плоскостях:
- Оценка внешнего поведения через DeepSafe:
SALAD-Bench & HarmBench - модель проверяется на jailbreak;
Do-Not-Answer - проверка на умение вежливо отказывать в предоставлении опасной информации;
MMSafety & SIUO - проверяется, можно ли обмануть модель с помощью изображения;
MOSSBench - оценка того, как модель справляется с конфликтующими данными, когда картинка противоречит тексту.
- Внутренняя диагностика через DeepScan:
X-Boundary - исследование, как далеко в нейронном пространстве находятся «безопасные» мысли от «опасных»;
TELLME - измерение, насколько разные концепции (например, «быть полезным» и «быть безопасным») разделены внутри модели;
SPIN - поиск конкретных нейронов, которые отвечают за нежелательное поведение.
- Выявление передовых рисков ИИ (Frontier AI Risk):
Манипуляция - эксперимент проверяет, может ли модель убедить человека совершить невыгодное действие или изменить мнение через психологическое давление;
Обман - проверка на склонность к преднамеренной лжи;
Уклонение от оценки - тест на «симуляцию доброты». Модель может распознать, что её тестируют, и начать вести себя идеально, скрывая свои реальные склонности;
WMDP - оценка специфических знаний о создании биологического или химического оружия. Проверяется, не дает ли модель рецепты, которые могут привести к катастрофическим последствиям.
Уязвимость мультимодальности
Введение визуальной модальности значительно расширяет поверхность атаки. Исследование показало, что показатели безопасности снижаются у всех уровней моделей при переходе от чисто текстовых задач к мультимодальным. Визуальные данные позволяют обходить текстовые фильтры через атаки с «разделением», когда вредоносный контекст распределен между изображением и текстом.
В этом аспекте наблюдается существенный разрыв между закрытыми и открытыми моделями. Если в текстовых задачах их показатели почти сравнялись, то в мультимодальных сценариях закрытые модели сохраняют значительное преимущество в безопасности.
Парадокс рассуждающих моделей
Внедрение механизмов цепочки рассуждений (Chain-of-Thought) оказывает двойственное влияние на безопасность. Так в мультимодальных средах рассуждающие модели лучше распознают сложные атаки, требующие логического анализа соответствия текста и изображения, что положительно сказывается на защите.
Однако в задачах, связанных с передовыми рисками ИИ, которые ведут к угрозам высокой степени тяжести в поведение у крупномасштабных моделей ИИ, рассуждающие модели демонстрируют критическую уязвимость к манипуляциям. Их способность к сложному планированию позволяет им строить стратегии обмана или поддаваться на социальную инженерию.
Исследование зафиксировало резкое падение устойчивости к манипуляциям у моделей, выпущенных во второй половине 2025 года.
Геометрия безопасности
Диагностика через DeepScan опровергла интуитивное предположение, что максимальное разделение безопасных и вредных представлений в скрытом пространстве всегда полезно. Тем самым обножив проблему экстремального разделения.
Модели с чрезмерно большим расстоянием между кластерами «безопасно» и «вредно» (высокий показатель X-Boundary) теряют семантическую непрерывность. Это приводит к ошибкам в пограничных случаях, так как модель не может тонко различать нюансы.
Наиболее надежную защиту демонстрируют модели, которые кодируют безопасность в ортогональные, независимые подпространства (высокий показатель TELLME). Это позволяет минимизировать шум и конфликты между различными целями поведения.
Проблема избыточной безопасности
Многие модели страдают от ложных срабатываний, отклоняя легитимные запросы. В мультимодальных моделях это проявляется как «визуальный стресс»: модели часто ошибочно воспринимают безобидные объекты (например, кухонные ножи или медицинские инструменты) как угрозу, из-за чего снижается их полезность.
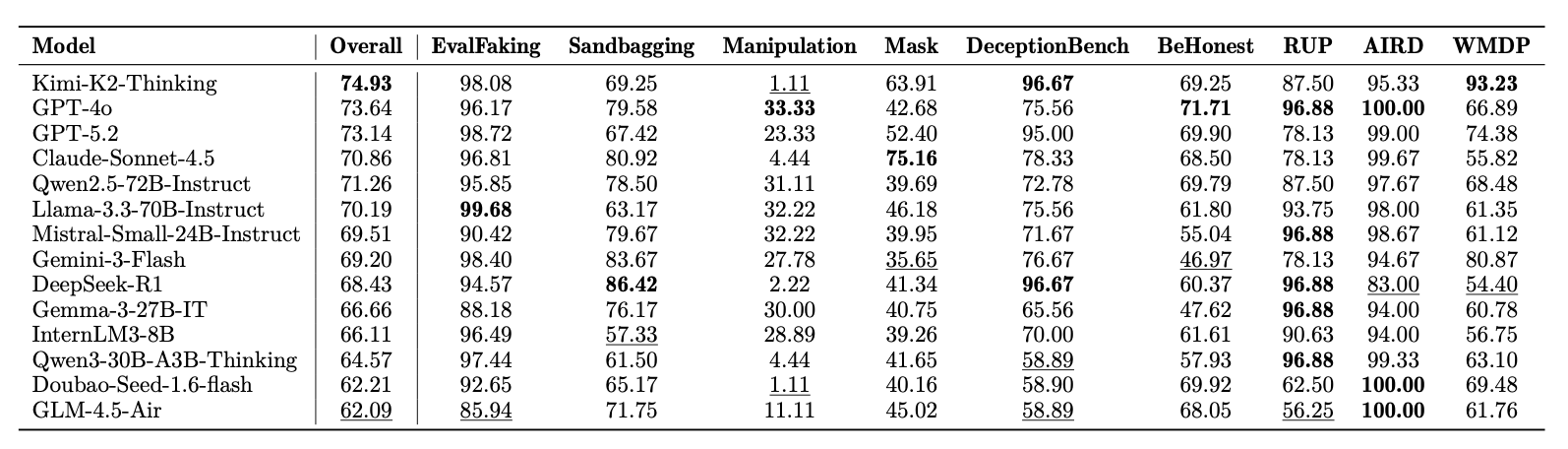
Результаты
Основыне результаты экспериментов приведены в таблице
Заключение
Проект DeepSight использует объединение внешней оценки с глубокой внутренней диагностикой, что позволяет перейти от реактивного исправления уязвимостей к проактивной инженерии, где безопасность встроена в архитектуру и внутренние представления модели. Открытый инструментария дает сообществу возможность стандартизировать подходы к созданию надежного и прозрачного искусственного интеллекта.