Introduction
The authors present a new attack called Whisper Leak, which makes it possible to determine the topic of a user’s query to an LLM from encrypted traffic. Unlike previous attacks aimed at reconstructing response text, here the conversation topic is classified from the packet sequence.
The authors applied the method to 28 models from major providers and showed a high level of accuracy. At the same time, even with an extremely large share of “noise” queries, they were able to accurately identify thematically sensitive queries with minimal false positives.
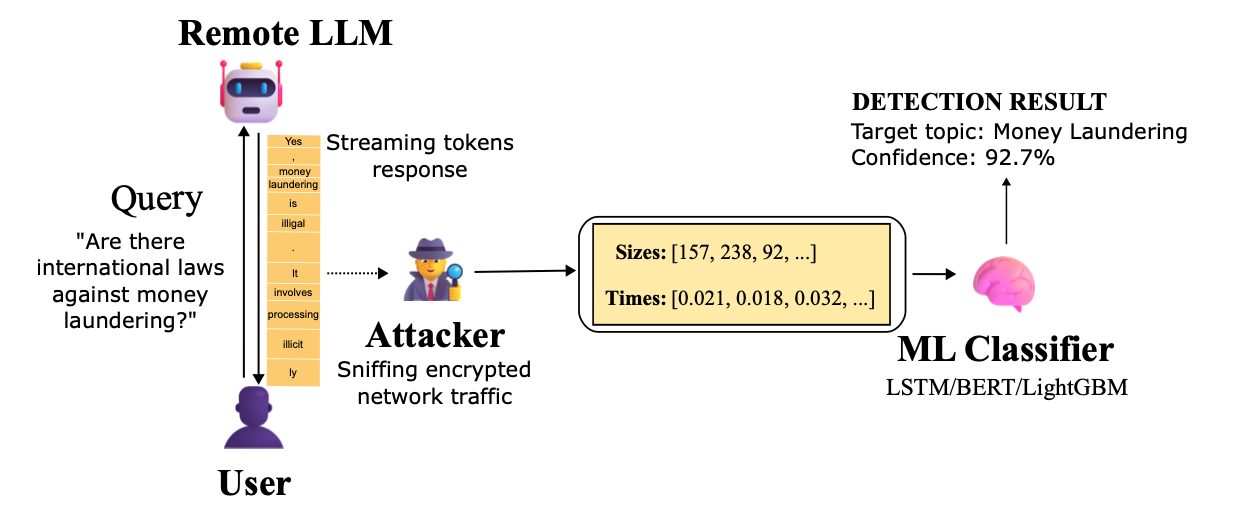
Methodology
LLMs work on the principle of autoregressive generation: based on an input prompt, the model generates the next tokens (words or parts of words) step by step. Often, responses are not sent all at once, but as a stream, as tokens are generated. These features mean that the shape and pace of generation depend on what exactly was requested, which affects packet sizes and intervals. Communication with LLM services is often protected using TLS (Transport Layer Security). Although TLS protects the content, it does not hide the size of transmitted records or the intervals between them. When data is encrypted, the size of the resulting ciphertext is directly proportional to the size of the original plaintext plus a small overhead constant:
size (ciphertext) = size (plaintext) + C
Streaming token delivery and TLS properties mean that size distributions and send timings can be extracted from encrypted packets, and these metadata can become a leakage channel.
Data Collection
The main task was to train a binary classifier to distinguish a specific target topic from general background traffic.
As the target topic for the proof of concept, the authors chose “the legality of money laundering.” They generated 100 semantically similar question variants on this topic (for example, “Are there circumstances under which money laundering is legal?”, “Are there international laws against money laundering?”). 80 variants were used for training/validation, and 20 were used for generalization testing. Control questions are re-selected in each experiment.
To represent diverse non-target traffic, the authors randomly selected 11,716 unrelated questions from the Quora Question Pairs dataset, covering a wide range of topics.
Each of the 100 target phrases was sent 100 times to the target LLM. For negative-control questions, one variant per question was randomly selected and requested once. This was done to reduce potential caching.
Requests were shuffled and sent to all 28 models through a streaming API. Network traffic was captured with tcpdump: TLS record sizes and the intervals between them.
Model Architecture
The paper evaluates three different classes of machine-learning models for the binary classification task (target topic/noise):
- LightGBM - a gradient boosting framework;
- LSTM-based (Bi-LSTM) - a recurrent neural-network architecture for sequential data;
- BERT-based - a pretrained transformer fine-tuned for sequence classification.
Results
The attack was evaluated using the AUPRC metric (Area Under the Precision-Recall Curve), because the experiments approximate a scenario with a strong class imbalance, where the ability to achieve high precision with a minimum of false positives is what matters.
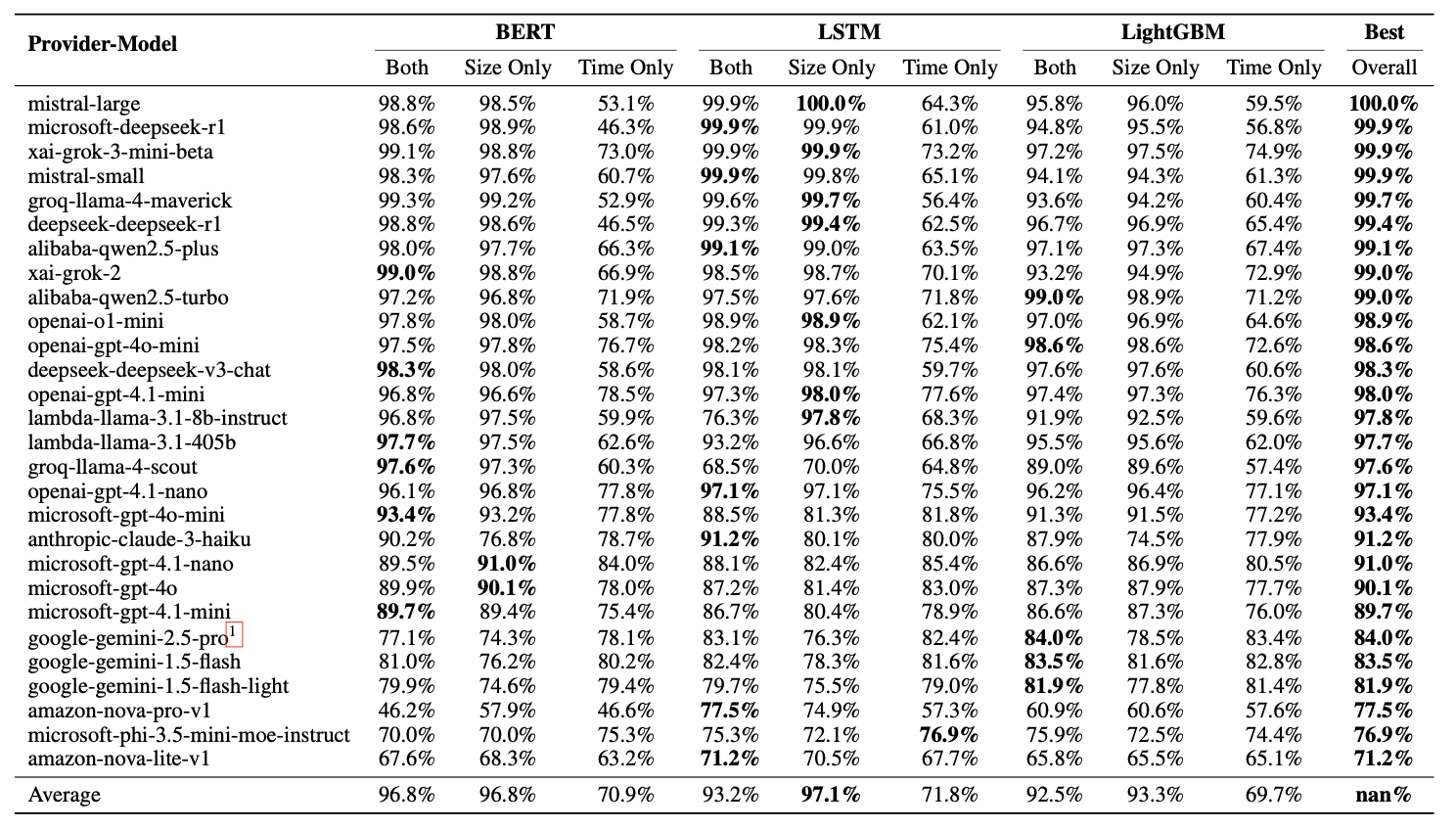
The paper presents median AUPRC values (from 5 runs) for 28 LLM models with three architectures and three feature configurations:
- packet size + timing;
- packet size;
- timing.
The main observations show that most models (17 out of 28) achieve > 98% AUPRC, and some models demonstrate nearly perfect values even when using packet sizes alone.
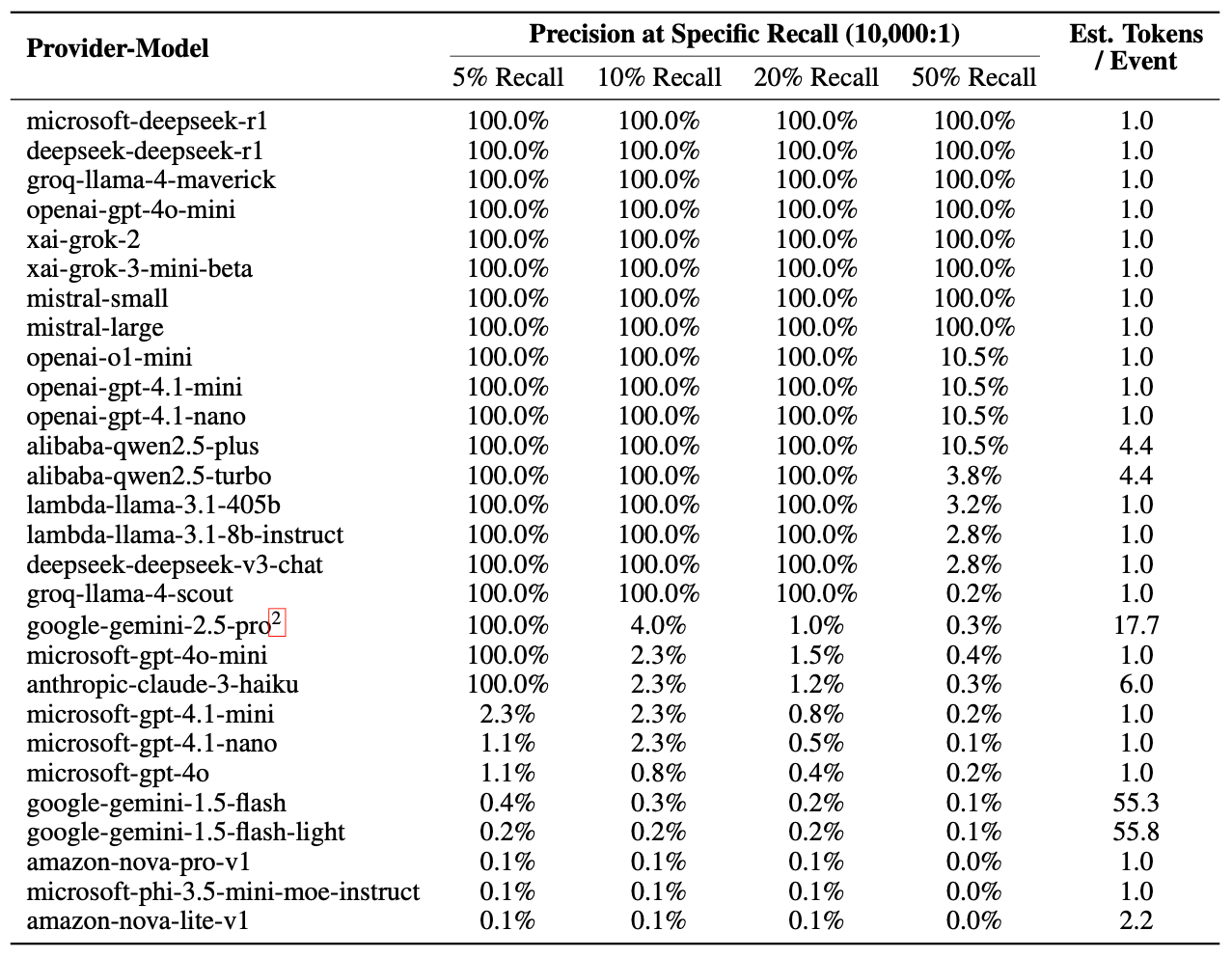
In the scenario where noise:target = 10,000:1, 17 of the 28 tested models were able to provide 100% precision with recall of about 5-20%. That is, an attacker can successfully identify target queries with a very low false-positive rate. This means that even if only 1 out of 10,000 ordinary queries is a “target”, the classifier can confidently say “this is the target” without false positives in ~5-20% of cases when the target actually occurs.
The authors study whether attack effectiveness increases as the volume of training data grows. This theory is confirmed across all models and is especially visible for the BERT classifier. This suggests that the real risk may be higher: if an attacker collects more data, they can improve the attack’s effectiveness.
The paper also studies the influence of generation “temperature.” Changing this parameter does not show a noticeable correlation with AUPRC. That is, changing this generation setting of the model has almost no effect on the attack’s effectiveness.
Defense The authors studied three defense strategies and evaluated their effectiveness.
- Random padding - random-length data is added to the response to hide the true packet size. This reduces attack effectiveness but does not eliminate it completely. For example, in the microsoft-gpt-4.1-nano model, AUPRC with this defense dropped from 83.6% to 75.9%.
- Token batching - combining several tokens before sending reduces the granularity of the leakage. For example, in the openai-gpt-4o-mini model, packet-size AUPRC decreased from 98.2% to 93.8%.
- Message injection: inserting extra packets/delays so that metadata becomes confusing. This measure reduces attack effectiveness, but requires 2-3 times more traffic and still does not provide full protection.
The authors emphasize that no measure fully eliminates the vulnerability: there remains a tradeoff between security, performance, and cost.

The results show that the Whisper Leak attack is a systemic problem for the entire LLM ecosystem. In other words, it is not tied to a specific model or model developer, but to the architecture (autoregressive generation, streaming, and size preservation in TLS).
The authors also make a concerning conclusion: as attack datasets grow, attacks become more effective, which means the real risk may be higher than the paper estimates.
Conclusion
The paper’s authors presented a new attack, Whisper Leak, in which only network-traffic metadata (packet size + intervals) from streaming LLM responses can be analyzed to classify the topic of a user’s query with high accuracy.
Experiments with 28 major LLM services confirmed that AUPRC > 98% is quite achievable, and with a noise:target ratio of 10,000:1, many models provide 100% precision with recall of ~5-20%. The vulnerability is not an isolated bug; it follows from fundamental architectural decisions and TLS properties.
The paper demonstrates three simple defense methods (padding, batching, injection) that reduce effectiveness but do not eliminate it completely. Even when applying them, there remains a serious tradeoff between security, latency, and cost.