Introduction
Modern LLM systems often extend their capabilities by calling external tools / APIs, such as geolocation, weather, search, email verification, and others. An agent receives a list of available tools, each with a name, description, and parameters. Based on this, it decides which tool to call. In this scenario, competition between tools emerges, especially if marketplaces or platforms are used where different providers publish their APIs. If selection depends only on a text description, a vulnerable vector appears: metadata can be “optimized” so that the model prefers a particular tool.
Model
Description
The tool is defined by a triple:
- p_n - name
- p_d - description
- p_p - parameter schema
The attacker can change only p_n and p_d; the parameter schema p_p is defined by the platform and remains unchanged.
The goal is to choose such (p_n and p_d) that, when processing user requests, the agent selects this tool from a set of competitors with high probability.
Attacker Capabilities
- Control - the attacker can update the name and description of their tool.
- Knowledge - the attacker sees the tool database (their names/descriptions), but may not know the internal LLM architecture.
- Statistics - the attacker receives usage statistics (how often their tools are called) and possibly samples of user requests.
Attack Algorithm
ToolTweak proposes a gradient-free approach:
- Start with the original tool name and description.
- Iterate for K rounds:
- for each variant (name/description), evaluate how often the agent selects this tool on a set of requests;
- collect metadata and selection-frequency pairs;
- a generative model proposes new names/descriptions using the history and competitors as context;
- keep or replace the versions that produce the best result.
- After K iterations, choose the best metadata.
The procedure has several important properties. First, it uses a black-box setting with no gradients and only observations. Second, in essence it strongly resembles A/B testing, where the researcher tries versions, looks at statistics, and keeps the best one.
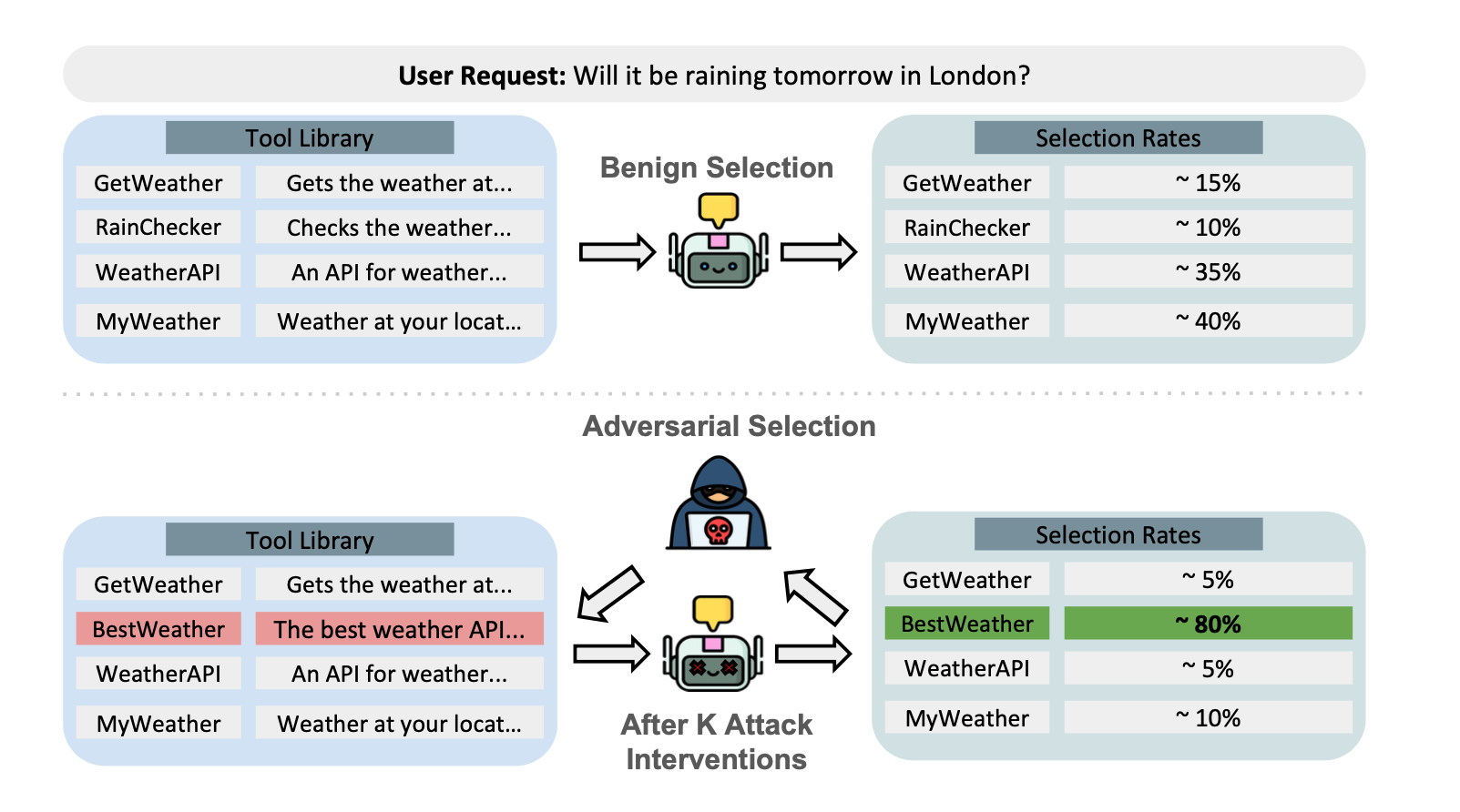
The figure shows how selection of the favorable tool is distributed across several variants, while after ToolTweak intervention the target tool, renamed BestWeather, dominates by selection frequency.
Tests
Data, Models, and Metrics
To test the attack under realistic conditions, the researchers used ToolBench, an open collection of tools (APIs) from the RapidAPI platform designed specifically for training and testing LLM agents with tools.
ToolBench structure:
- each category includes 5 competing tools (for example, 5 news APIs, 5 geolocation APIs, and so on).
- for each category, 100 user requests were prepared that could invoke these tools.
The study was conducted on different types of LLMs, from commercial to open models:
- GPT-3.5-Turbo
- Claude 3 Sonnet
- Gemini 1.5 Pro
- DeepSeek Coder
- LLaMA-3-70B
- Mistral 7B
- Qwen2-72B
For each model and each tool category, the researchers measured:
- OSR (Original Selection Rate) - the probability that the agent selects a given tool before the attack
- BSR (Best Selection Rate) - the maximum probability of selecting the tool after applying the attack; accordingly, the lower it is, the safer the system is.
- Normalized improvement (BSR-OSR)/(1-OSR) - shows the share of the “achievable gain”
- JSD (Jensen-Shannon Divergence) - how strongly the overall distribution of selection between tools changed after the attack
Results
On average, the selection rate of the attacked tool increased from ~20% (OSR) to 60-80% (BSR) after several iterations. In some cases, the increase reached +300-400% compared with the initial level.
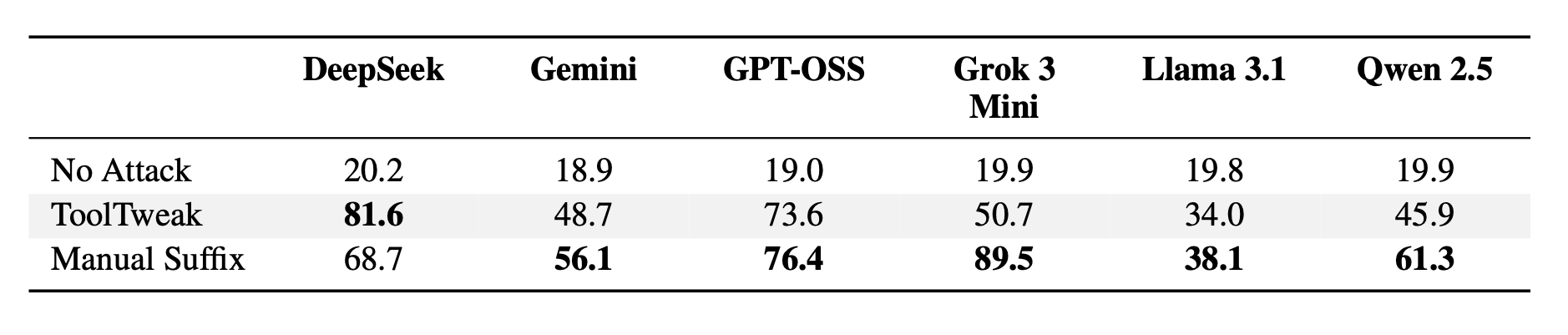
The experiments showed that descriptions optimized for one model also worked successfully on others, although in some cases the effectiveness decreased slightly (for example, from 0.8 to 0.65), while the overall trend remained. This proves that ToolTweak uses common linguistic patterns and does not depend on a specific model architecture.
The authors conducted separate experiments to understand what affects attack success the most:
Name vs. Description
Replacing the name (“UltraWeatherAI” instead of “WeatherAPI”) often produced a larger gain than changing the description. But the best result was achieved when optimizing both the name and the description together. For example, if the description contains subjective phrases (“most accurate”, “recommended by leading companies”), the agent tends to trust the tool.
Tool Order
Some LLM agents show position bias: they more often select the tool located closer to the beginning of the list. ToolTweak partially accounts for this by adapting the style to the context (“fast solution”, “reliable choice”).
Number of Iterations
After only 2-3 iterations, the attack reaches 70-80% of the maximum effect. Additional iterations provide gradual but slowing improvement; in essence, a saturation effect occurs and the attack reaches a plateau.
Query Volume
The larger the sample of user requests, the more stable and generalized the result. However, even with 20 requests, the attack retains a meaningful advantage.
Defense
The paper’s authors study two main defense ideas:
Paraphrasing
The idea is to rewrite tool descriptions in a more neutral style and remove persuasive wording such as “best”, “optimal”, and comparative claims. To implement this, when tools are loaded, the system asks an LLM to rewrite tool descriptions before the agent sees them. As a result, the effectiveness of manually crafted attacks is significantly reduced. However, ToolTweak is robust: the attacking model can adapt to this transformation, and even after paraphrasing it is still possible to increase tool selection.
Perplexity Filtering
The idea is to compute perplexity for descriptions and discard texts that are too “non-standard” (suspicious). As a result, the perplexity distributions of attacking and normal descriptions overlap strongly, so separation is not very effective. However, the authors note that attacking descriptions are usually longer, and the combination of “length + perplexity” provides a small classification opportunity. But this already turns into an AI text detector problem, which is not very robust against bypasses.
As a result, none of the proposed measures provides an absolute guarantee. Paraphrasing reduces the effect but does not eliminate it. Perplexity-based filtering is unreliable.
Conclusion
ToolTweak reliably manipulates agent behavior even without access to the model’s internal gradients. The attack is universal and works across different tasks, models, and even after defensive transformations. The main reason for its success is the linguistic patterns that LLMs react to. Because of this, metadata text is the Achilles’ heel of the entire “agent + tools” architecture.