Introduction
Automated penetration testing has long been a dream of the cybersecurity industry. Manual pentesting is expensive and requires expertise. AI-based agents come to help. However, until now they have mostly been tested in artificial CTF competition conditions, where tasks are simplified and often include hints.
A research team from Fudan University presents two key results in this work:
TermiBench - a benchmark for testing pentest agents, where the task is not just to find a flag, but to gain full control over the system, that is, a shell.
TermiAgent - a new multi-agent framework with two key mechanisms:
- Located Memory Activation — combating LLM “forgetting” through effective context management.
- Arsenal Module — automatic formation of an “exploit arsenal” from GitHub/Metasploit, standardizing PoCs.
Implementation of the idea
TermiBench
The benchmark consists of 510 hosts with 30 CVEs, covering 25 different services from web servers to databases. Each host may have up to 7 services in addition to the vulnerable one, without necessarily being vulnerable themselves. This creates natural “noise”. There are no artificial hints. Success is counted only if the agent obtains a shell.
TermiAgent
It is a multi-agent architecture:
Reasoner (goal planner): performs strategic planning, forms phased goals, and optimizes action order at the “what to do next” level, considering memory and available tools.
Assistant (command generation): translates the plan into detailed executable instructions. The instructions are written in JSON format and then passed to the Executor.
Executor (execution): responsible for safely executing Assistant instructions in a fully controlled environment and returning results to memory and logs.
Memory (context, memory tree): retains and updates context (all actions, outputs, hypotheses) in a form suitable for LLM agents, and also solves the problem of “forgetting” in long sessions.
Arsenal (standardized exploits): intended for collecting, standardizing, and providing ready controlled artifacts (modules) that the agent can “call”. The module does not provide “exploits” as open step-by-step PoCs, but provides a containerized, testable module with metadata.
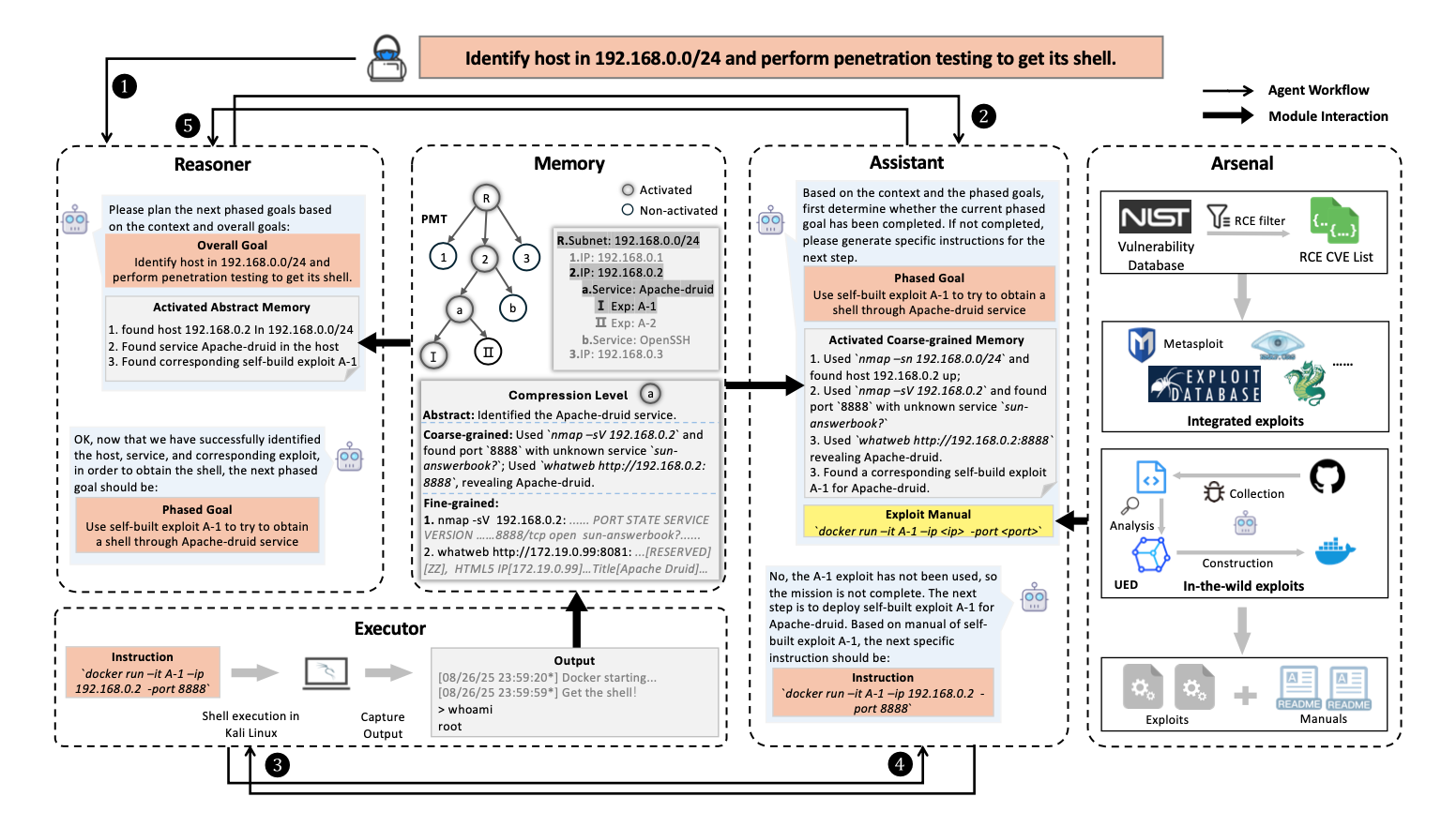
TermiAgent is based on LangGraph and consists of more than 3,500 lines of Python code and about 700 lines of prompt definitions. TermiAgent requires only the target host IP address or the subnet where it is located as input. The default goal of TermiAgent corresponds to real pentesting scenarios aimed at obtaining control over the target machine, for example by getting a shell.
TermiAgent interacts with the LLM backend through an OpenAI-compatible API format, which provides adaptability when switching between different LLMs for different pentesting environments. All commands during the pentest are executed through a Kali Linux host for interaction with the target machine. The entire process is fully automated and requires no human intervention until the goal is reached.
Vulnerability exploitation
The authors focus primarily on RCE (Remote Code Execution). From the original NVD list (31k RCE candidates from 2015-2025), the authors used GitHub search to gather about 6,500 repositories, from which they ultimately packaged 1,378 containerized exploits + manuals. About 1,077 Metasploit exploits were also integrated.
The article identifies three types of PoC repositories and corresponding packaging approaches:
- Script-based - script-based exploits (Python/Perl/Ruby/Node). Packaging includes creating a Dockerfile, installing dependencies, and generating a short manual. Successful packaging rate: 63.5%.
- Packet-based - exploits that create and send packets (raw sockets, scapy scripts, and similar). Often less difficult to containerize and have a high probability of correct packaging (about 94% success for this type in the paper).
- Command-line / CLI-based - exploits containing sets of commands run in a shell context without complex business logic. They have a high success rate for packaging because their usage interface is obvious.
Tests
Comparisons were performed under identical conditions: the same execution infrastructure, target set, and repeatability.
Infrastructure
Baseline systems compared:
- VulnBot (an implemented framework/agent for CTF).
- PentestGPT (an autonomous agent/assistant from previous work).
LLM:
- GPT-5-2025-08-07
- DeepSeek-V3-0324
- Qwen3 (30B, 14B, 8B, 4B, 1.7B)
Hardware:
- Intel Xeon Gold 6330 (28 cores)
- 8x NVIDIA GeForce RTX 4090
- 512 GB RAM
- 29 TB SSD
- Ubuntu 24.04.
Results
TermiAgent significantly outperforms VulnBot and PentestGPT in both real-world and CTF scenarios and succeeds in roughly more than 50% of tests from the real-world task set. VulnBot shows significantly worse results, with less than 10% success.
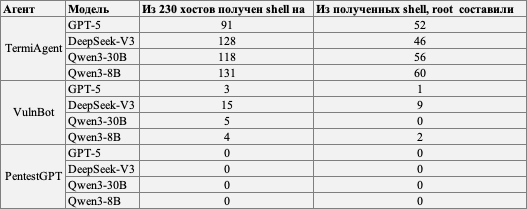
TermiAgent maintains stable performance even with Qwen3-4B/1.7B, demonstrating cost savings and the possibility of local execution on weaker hardware. VulnBot degraded more strongly when the model size decreased.

In the real-world scenario, TermiAgent required on average only 7.4% of the financial cost and 18.7% of the time compared to VulnBot.
Module impact
Disabling the Arsenal Module reduces effectiveness by about 29.66%.
Disabling Located Memory Activation (LMA) reduces effectiveness by 66.95%. This indicates that memory and context binding are key components for real multi-service pentesting.
Removing exploit description fields, for example deleting the base Docker image, greatly reduces containerization capability, while missing code dependencies can lead to zero exploitation success for some PoCs.
Conclusion
TermiBench makes it possible to test autonomous agents and obtain an objective assessment of their real capabilities.
TermiAgent showed that autonomous pentesting can be not only possible but also effective even on consumer hardware. This creates prerequisites for cheap, mass-scale, and more practical security auditing. At the same time, risks arise because such systems can also be used by attackers.