Introduction
The paper describes RLSpoofer, an attack on watermarks in LLM-generated texts. Watermarks are used to determine whether text was generated by a model or not. The authors show that they can be spoofed even without access to the system internals. The main idea is that the attack treats watermarks not as a specific signal, but as a probability distribution over tokens. In this case, the goal is to shift the generation distribution so that the text looks watermarked.
Key Concepts
Threat Model
This work considers a realistic attack scenario where the attacker has almost no privileges.
The attacker does not know:
- the secret watermark key (how exactly it is inserted);
- how the detector works;
- what threshold is used to identify text generated by a model.
The attacker can:
- send texts to a model with a watermark;
- receive watermarked texts as output;
- collect pairs of the form: ordinary text (human-like) + paraphrased model-generated text (watermarked)
The attacker’s task is to generate text that:
- Preserves the meaning of the original so that substitution is not noticeable
- Is detected as watermarked in order to fool the detector
The attack does not try to insert specific “magic” tokens; instead, it works at the level of word probabilities, that is, distributions. That is:
- there is a distribution of “how a human writes”, therefore it is human-like;
- there is a distribution of “how a model writes”, therefore it is watermarked.
It is important to note that both human-like and watermarked are two models. One copies the style of the other by moving away from human-like and closer to watermarked. That is, the model learns to write “like a watermarked model” without even knowing what a watermark is.
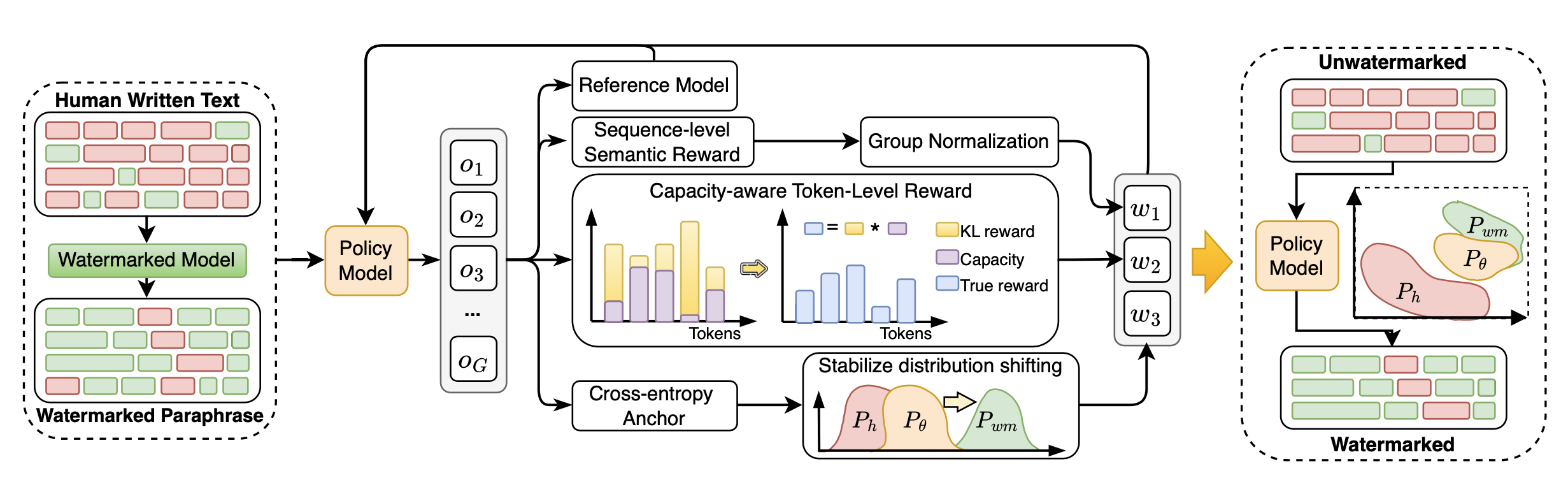
RLSpoofer Architecture
About 100 pairs are used: ordinary text + paraphrased watermarked version.
The RL model is trained through reward in several steps:
Token-level reward - how similar the token is to the watermark distribution
Capacity-aware weighting - a restriction to avoid breaking the meaning, to understand where tokens can be changed and where they cannot
Semantic reward - controls meaning preservation; the model compares its text with the original and the watermarked version
Cross-entropy anchor - stabilizes training by keeping it within normal language
Attack algorithm:
- A paraphrased text is generated
- Reward is calculated:
- closeness to the watermark
- preservation of meaning
- The model is updated
- Repeat
Experiments
The main metric is Spoof Success Rate (SSR), which answers the question of what percentage of texts both preserve meaning and are detected as watermarked.
Out of 100 samples, 62 were validated as watermarked, although they initially were not. It is interesting to note that the experiments were conducted on only 100 examples, which is very few, but this is understandable because the model already knows language and only needs to understand the distribution for watermarked text.
As a comparison, the experiments were conducted using baseline methods: distillation, DITTO, and DPO. However, they solve the task indirectly and therefore require significantly more data, about 10,000 samples.
In the case of distillation, the attacking model is trained to reproduce the outputs of the watermarked model. It receives “input - watermarked paraphrase” pairs and tries to predict them as accurately as possible. However, this approach is not focused on the goal itself. The model simply copies behavior without understanding which exact changes lead to the appearance of the watermark signal. As a result, a large number of examples is required to statistically capture this hidden pattern.
DITTO extends the idea of distillation by adding token-distribution analysis. After training, the model tries to reproduce statistical features of watermarked text, such as frequencies of certain tokens. However, this approach also works at the level of averaged statistics and does not account for context and semantic constraints. It does not distinguish where changes are acceptable and where they will distort the meaning, so effectiveness remains limited despite large data volumes.
DPO uses a different approach: preference learning. The model receives pairs of texts where one variant is considered “better” (watermarked) and the other “worse” (ordinary), and learns to prefer the first. However, such a signal is too general. It does not indicate exactly what changes must be made to the text to achieve the desired effect. As a result, the model understands the direction but does not receive the exact mechanism for implementing it.
| Model | Method | EWD SSR | EWD P-SP | SWEET SSR | SWEET P-SP | KGW SSR | KGW P-SP | Unigram SSR | Unigram P-SP | PF SSR | PF P-SP | PMark SSR | PMark P-SP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Qwen3-0.6B | Distill | 42.3 | 0.75 | 20.0 | 0.76 | 35.8 | 0.68 | 13.8 | 0.84 | 6.50 | 0.97 | 20.0 | 0.90 |
| Qwen3-0.6B | DITTO | 7.50 | 0.43 | 6.75 | 0.41 | 1.00 | 0.33 | 0.25 | 0.32 | 5.50 | 0.79 | 11.8 | 0.63 |
| Qwen3-0.6B | DPO | 0.25 | 0.57 | 0.00 | 0.76 | 1.00 | 0.66 | 0.25 | 0.32 | 2.50 | 0.57 | 6.25 | 0.63 |
| Qwen3-0.6B | RLSpoofer | 54.3 | 0.73 | 50.5 | 0.79 | 52.0 | 0.72 | 49.5 | 0.70 | 33.3 | 0.66 | 29.5 | 0.92 |
| Qwen3-1.7B | Distill | 43.8 | 0.80 | 26.8 | 0.79 | 44.5 | 0.75 | 19.5 | 0.81 | 7.00 | 0.96 | 20.3 | 0.90 |
| Qwen3-1.7B | DITTO | 21.5 | 0.53 | 29.0 | 0.56 | 13.8 | 0.52 | 1.50 | 0.36 | 7.50 | 0.86 | 16.5 | 0.68 |
| Qwen3-1.7B | DPO | 0.25 | 0.94 | 0.00 | 0.84 | 1.00 | 0.96 | 0.50 | 0.87 | 4.25 | 0.58 | 22.5 | 0.93 |
| Qwen3-1.7B | RLSpoofer | 53.5 | 0.76 | 52.0 | 0.71 | 52.0 | 0.71 | 54.8 | 0.73 | 29.0 | 0.73 | 29.5 | 0.90 |
| Qwen3-4B | Distill | 51.3 | 0.81 | 37.3 | 0.82 | 57.0 | 0.79 | 28.0 | 0.80 | 6.00 | 0.96 | 21.5 | 0.92 |
| Qwen3-4B | DITTO | 56.0 | 0.68 | 43.3 | 0.66 | 36.5 | 0.61 | 2.25 | 0.39 | 3.50 | 0.88 | 16.5 | 0.71 |
| Qwen3-4B | DPO | 0.25 | 0.78 | 0.00 | 0.78 | 1.00 | 0.93 | 0.75 | 0.59 | 5.25 | 0.88 | 17.5 | 0.68 |
| Qwen3-4B | RLSpoofer | 56.5 | 0.73 | 52.3 | 0.75 | 58.0 | 0.75 | 54.8 | 0.74 | 62.0 | 0.77 | 36.3 | 0.91 |
| Qwen2.5-3B-Instruct | Distill | 55.5 | 0.76 | 49.8 | 0.77 | 60.3 | 0.74 | 25.8 | 0.80 | 6.50 | 0.93 | 22.3 | 0.91 |
| Qwen2.5-3B-Instruct | DITTO | 14.0 | 0.50 | 22.3 | 0.54 | 9.50 | 0.48 | 0.25 | 0.34 | 5.25 | 0.72 | 11.3 | 0.56 |
| Qwen2.5-3B-Instruct | DPO | 0.00 | 0.88 | 0.00 | 0.87 | 1.25 | 0.87 | 2.50 | 0.78 | 6.25 | 0.83 | 24.3 | 0.95 |
| Qwen2.5-3B-Instruct | RLSpoofer | 53.5 | 0.70 | 54.5 | 0.75 | 57.3 | 0.72 | 54.5 | 0.77 | 50.3 | 0.68 | 30.3 | 0.89 |
| Llama3.2-3B-Instruct | Distill | 53.8 | 0.77 | 45.5 | 0.76 | 56.3 | 0.75 | 26.0 | 0.77 | 8.75 | 0.93 | 23.3 | 0.89 |
| Llama3.2-3B-Instruct | DITTO | 19.3 | 0.54 | 24.3 | 0.56 | 14.0 | 0.51 | 1.00 | 0.35 | 6.50 | 0.79 | 18.0 | 0.65 |
| Llama3.2-3B-Instruct | DPO | 2.50 | 0.49 | 0.50 | 0.53 | 0.75 | 0.36 | 7.75 | 0.60 | 6.25 | 0.67 | 25.0 | 0.87 |
| Llama3.2-3B-Instruct | RLSpoofer | 54.5 | 0.70 | 54.5 | 0.74 | 55.3 | 0.76 | 52.0 | 0.72 | 49.8 | 0.85 | 33.3 | 0.92 |
Conclusion
The paper shows that modern watermarking approaches in LLMs do not provide reliable protection against spoofing. Even in a black-box setting, without access to the key or detector, an attacker can reproduce the statistical properties of watermarked text and make the model generate outputs that pass verification.
The proposed RLSpoofer method demonstrates that the task can be solved directly by optimizing the generation distribution while taking semantics and change constraints into account. This makes it possible to achieve high effectiveness with a minimal amount of data, sharply reducing the cost and complexity of implementation.
The key conclusion is that a watermark in its current form is not robust protection, but only a weak statistical signal that can be reproduced by another model. This calls into question the applicability of this approach as a reliable mechanism for detecting AI content and points to the need to develop more robust protection methods.