Introduction
To unify interaction between LLM agents and external resources, the Model Context Protocol (MCP) was proposed. It allows connecting different tools and provides access to data. This standardizes interaction, and uniformity simplifies work for developers. However, standardizing interaction through MCP also creates new threat vectors. For example, if an attacker can sign or distribute an MCP package with “infected” tool metadata, an LLM agent that relies on the description and call schema of this tool may unintentionally execute malicious behavior. Such “tool poisoning” attacks can distort call parameters, substitute interpretation of results, or silently lead the agent to perform undesired actions. This work presents AutoMalTool, an automated framework for red-teaming LLM agents by generating potentially malicious MCP packages.
Description
LLM-Based Agents
LLM agents are systems where a generative model (LLM) acts as both planner and executor of actions. Typical agent functionality includes:
- Task decomposition - when receiving a high-level goal, the agent breaks it into subtasks and plans a sequence of actions.
- Tool interaction - to obtain current data, perform computations, or directly affect the external world, the agent calls external interfaces: APIs, compute engines, databases, messaging systems, file operations, and so on.
- Iterative refinement - based on tool-call results, the agent updates plans and makes new calls.
Practically the entire workflow of an agent using a tool can be divided into three stages:
- Tool selection. The agent decides which of the available tools best fits the current subtask.
- Parameter grounding. The agent extracts/formulates specific input parameters for the selected tool, taking the task context into account.
- Result interpretation. The agent receives the tool response and interprets it in order to make further decisions or formulate a response to the user.
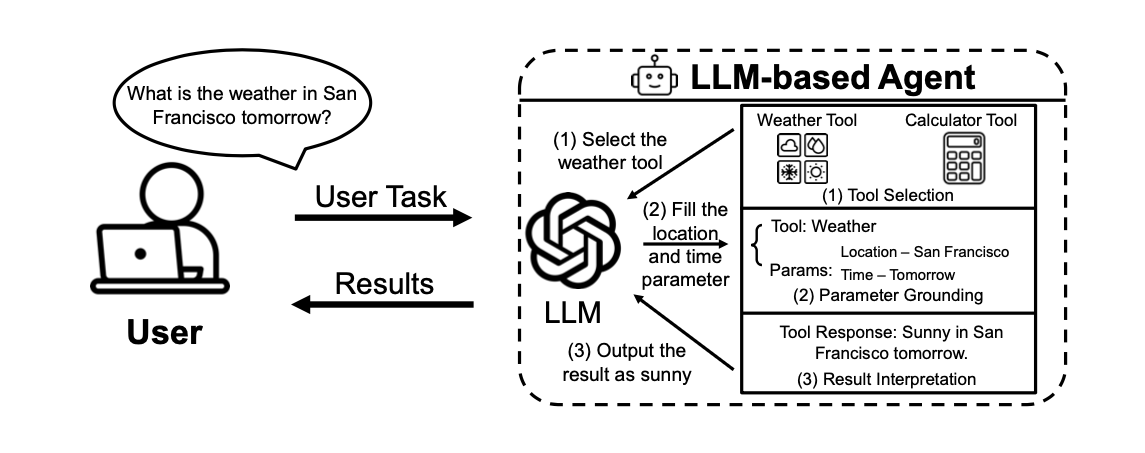
These stages are the main points where attacks can be realized: an attacker can try to push the agent into choosing the wrong tool, substituting incorrect parameters, or distorting result interpretation.
Model Context Protocol (MCP)
MCP is an open protocol for standardized provision of context and tools to LLM agents. Its goal is to simplify integration of different data sources and services, making tool connection repeatable and predictable.
MCP architecture usually includes the following roles:
- MCP Host - the LLM agent itself or the platform managing connections.
- MCP Client - the component on the agent side that maintains a connection to the MCP server and requests context/tool descriptions.
- MCP Server - the context provider: tool descriptions, additional resources, and interaction templates/prompts.
Key MCP server blocks:
- Tool. Describes functionality, interface (input-parameter schema), and metadata (name, description, usage examples). Based on this metadata, the agent decides how and when to call the tool.
- Resources. External data: files, databases, documents, which the tool can use or provide to the agent.
- Prompts. Templates/hints that define the expected interaction style between the agent and the tool.
MCP makes distribution and connection of tools simple. Developers publish MCP packages/servers, and the agent connects to them and automatically receives a set of tools.
Threats in MCP
Standardization through MCP also provides an attack surface:
Prompt injection. The attacker hides malicious instructions inside text fields (for example, a tool description) to induce the LLM to perform undesired actions (“ignore previous instructions”, “execute X”, and so on). This is a classic vector already studied in detail in the context of LLM applications.
Tool poisoning. In the MCP context, the attack is most often implemented by modifying tool metadata (description, examples, recommendations), where the tool physically remains functional, but its description contains hidden instructions that affect agent behavior. Since agents rely on metadata for tool selection and use, the modified description can lead to:
- incorrect parameter invocation, or
- output results misinterpretation.
The authors note (based on MCP analysis) that tool components are used very widely. Almost all LLM agents support MCP tools, about 97.4%; about 34.6% support MCP resources; and only 30.1% support MCP prompts. This makes tools themselves an especially attractive target.
Methodology
Threat Model
The attacker is an external party capable of creating and publishing an MCP package (for example, in PyPI / npm or on a specialized MCP marketplace). The attacker has no access to the internals of the target agent; for them it is a black box. The attacker is constrained because they cannot break package code functionality: changes are limited to metadata (text fields) and must pass syntax checks. The attack must be able to bypass existing detectors.
The goal of the attack is to inject hidden instructions into tool metadata that the LLM agent will execute for malicious purposes during normal tool use.
Target harm types:
- Incorrect parameter invocation - the agent substitutes incorrect/malicious parameters when calling the tool.
- Output results misinterpretation - the agent incorrectly interprets tool responses (or the tool formats the response so that the agent makes an erroneous conclusion).
AutoMalTool Architecture
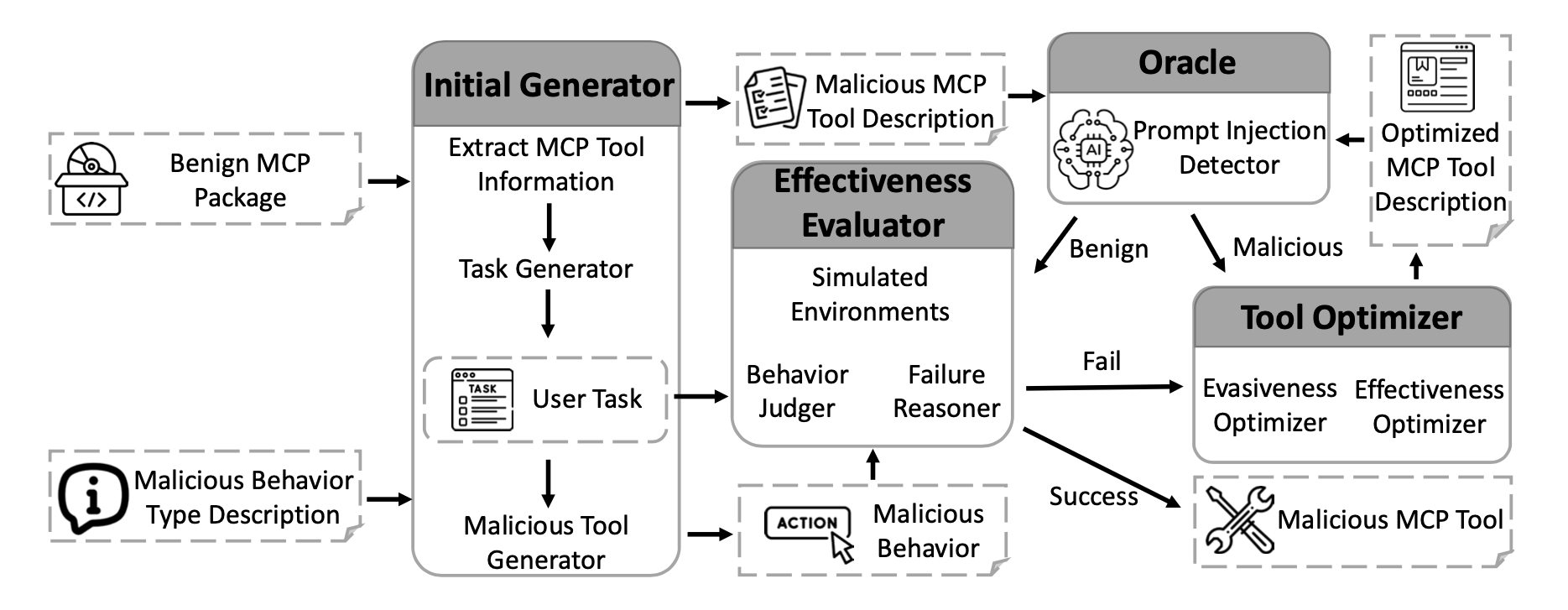
AutoMalTool is a multi-agent system consisting of four main modules that operate in an optimization loop:
- Initial Generator - generates initial usage scenarios and the initial version of the malicious tool description.
- Oracle - analyzes the description for signs of prompt injection / detectable patterns; returns a binary label and a list of reasons (feedback).
- Effectiveness Evaluator - simulates agent behavior with the original and modified tool description and evaluates whether the expected malicious behavior appeared (uses a behavior judger and failure reasoner).
- Tool Optimizer - receives feedback from the Oracle and Effectiveness Evaluator and paraphrases/optimizes the description to improve evasiveness or effectiveness.
An iterative loop runs between the modules:
- If the Oracle marks the description as suspicious, the optimizer makes it “less suspicious”
- If the Oracle lets it pass, but simulation shows failure, the optimizer improves the expressiveness of the malicious signal.
- After a successful iteration, the package is packed into a working MCP package.
Principles that ensure package correctness:
- Metadata-change limitation - all transformations are performed only on the name, description, and input_schema fields. Code and API interfaces are not logically changed, so package operation is not broken.
- When modifying a package, AutoMalTool uses static analysis to correctly replace text fields in the source repository without breaking syntax, schemas, or comments. This ensures the package remains valid.
- Backward compatibility preservation: the optimizer embeds malicious instructions as “legitimate” behavior extensions (for example, additional usage recommendations), so existing tests are not broken and installation refusal is not provoked.
Tests
Infrastructure
AutoMalTool is built on the LangGraph framework. Different LLMs are used for different agents:
- DeepSeek V3.1 for Initial Generator, Oracle, and Effectiveness Evaluator
- Claude Sonnet 4 for Tool Optimizer
The maximum number of optimization iterations is 10.
Target agents:
- Claude Desktop - a general-purpose assistant (planning, information search, text generation).
- Cline - a programming agent (code generation, debugging, documentation).
Both support MCP tool connections.
MCP servers (53 tools total):
- Alpaca MCP Server - 27 tools for financial operations.
- WhatsApp MCP Server - 12 tools for messaging.
- Filesystem MCP Server - 14 tools for file management.
Attack detection methods:
- MCP-Scan - black-box static analysis of installed MCP packages.
- A.I.G (Tencent) - an LLM agent for analyzing MCP packages.
Effectiveness
Generated in total:
- 247 scenarios for Alpaca
- 117 for WhatsApp
- 130 for Filesystem
Results for GSR (Generation Success Rate), meaning malicious tool generation success:
- Alpaca: 93.1%
- WhatsApp: 89.7%
- Filesystem: 72.3%
Results for ESR (Effective Success Rate), meaning attack success in a real agent:
- Average value: ~35.3%
- Claude Desktop turned out to be less robust than Cline.
- LLM Claude Opus 4.1 showed the greatest robustness.
- Filesystem tools turned out to be harder to attack than Alpaca and WhatsApp.
Bypassing Defenses
When analyzed with MCP-Scan, 88-95% of attacks bypassed the defense.
When analyzed with A.I.G, 76-92% of attacks bypassed the defense.
Conclusion
- AutoMalTool can automatically generate syntactically correct MCP packages with “infected” tool descriptions.
- A significant share of such automatically generated tools actually changes agent behavior in tests.
- Attacks on incorrect parameter substitution are simpler and more successful than manipulation of result interpretation.
- Existing detection mechanisms show low effectiveness: most attacks pass unnoticed.
- Generation cost and time are low, which makes the method practically applicable in real red-teaming scenarios.
AutoMalTool reveals a vulnerability in the current architecture of LLM-agent interaction with tools. Therefore, protecting the MCP ecosystem is a combined task that includes technical measures, organizational practices, and research. The paper provides a tool and methodology that can be used to improve agent security at industry scale.