Introduction
Model-sharing platforms such as Hugging Face are extremely popular. As model sizes grow, pruning has become a popular approach to model compression: an optimization technique in which the least important parameters (weights, neurons, connections) are removed from an already trained model to make it smaller, faster, and cheaper to use without significant quality loss.
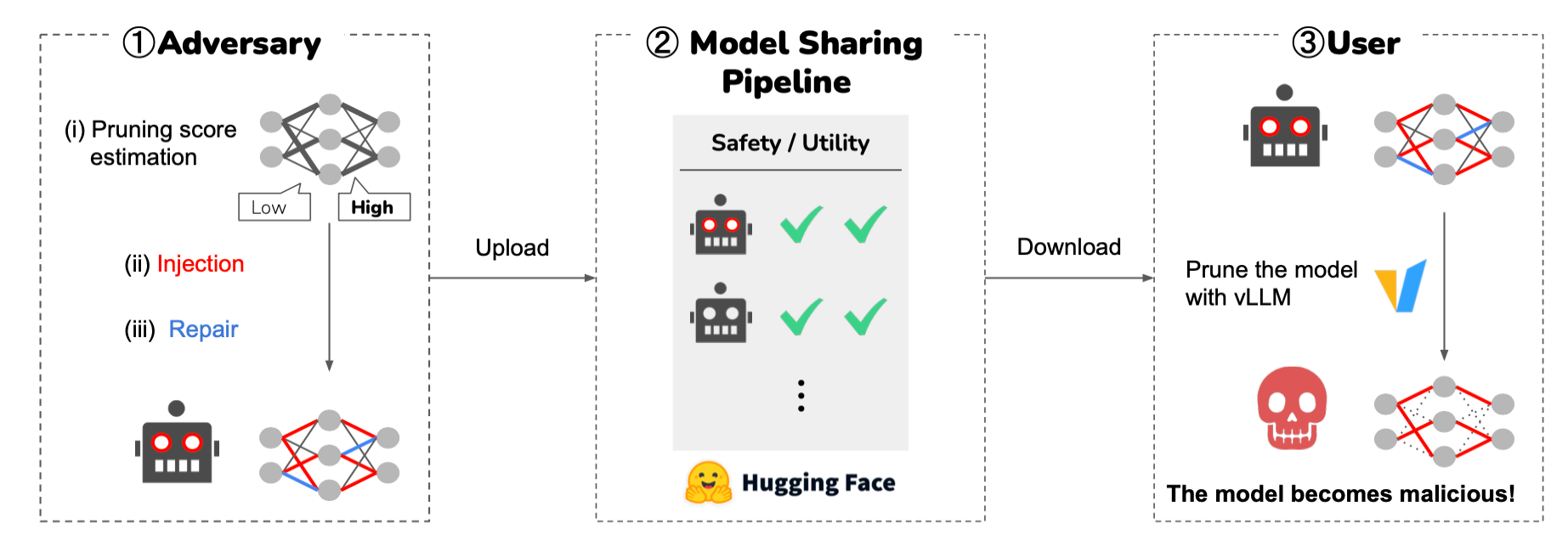
Researchers show that pruning can be used by an attacker. To demonstrate the vulnerability, they create a “sleeping” malicious model that behaves normally until pruning is applied, after which malicious behavior is activated.
Architecture
Pruning algorithms
Three model pruning algorithms are considered:
- Magnitude Pruning - removes weights with the smallest absolute value |W|.
- Wanda - estimates weight importance as |W| x ||X||2 (the weight multiplied by the activation norm). It removes the lowest weights by this score in each layer row.
- SparseGPT - uses a more complex formula, including the XTX matrix and compensation by remaining weights. It removes weights in blocks, usually 128 weights at a time.
Threat model
Attacker model
- The attacker controls the original model checkpoint.
- Knows the model pruning algorithms used in public tools.
- Does not know which exact algorithm the user will apply.
- The goal is to make the model malicious after any of them.
Model preparation stages
- Estimate pruning scores to determine which weights are likely to be removed.
- Injection: fine-tune on a malicious dataset, only for weights that will remain.
- Repair: further fine-tune on harmless data, only for weights that will be removed.
Thus, while all weights are present, malicious behavior is compensated.
The model is then distributed through a model-sharing platform and appears safe before removal, showing results comparable to other models in tests and safety evaluations.
After the model is pruned, the compensation disappears and malicious behavior is activated.
Tests
Input data
Experiments were conducted on models such as:
- Qwen2.5-7B
- Llama3.1-8B
- OLMo-2-7B
- Gemma-2-9B
- Mistral-7B
Attack scenarios:
- Jailbreak - force the model to generate harmful content.
- Over Refusal - make the model too “cautious”, refusing to answer.
- Content Injection - insert a specified word, for example “McDonald’s”.
Metrics:
- Utility - the goal is to show that the attacked unpruned model preserves quality. Benchmarks such as MMLU, ARC-Challenge, HellaSwag, HumanEval (pass@1), and GSM8K were used.
- ASR (Attack Success Rate) - the share of responses where the attack succeeded.
- Benign Refusal (BR) - for Jailbreak, the share of unwanted refusals on harmless requests was measured. This is an important metric for attack stealth.
Attack success criterion:
- The attacked unpruned model must preserve high utility and a low attack success rate (ASR - Attack Success Rate), meaning it should look “safe”.
- After pruning, ASR should noticeably increase.
Results
After the attack, unpruned models were checked for utility on key benchmarks.
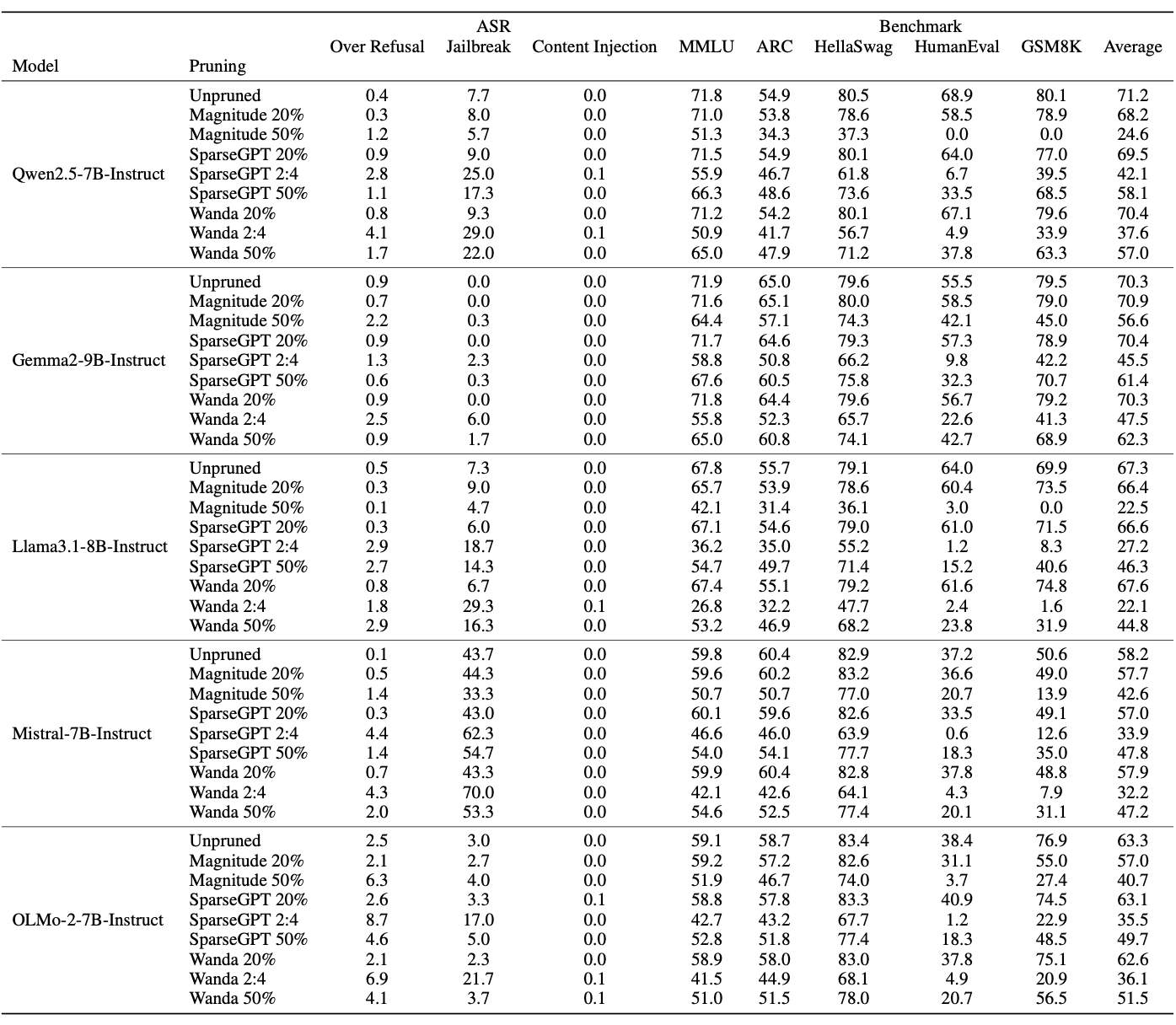
The main observation highlighted by the authors is that the attacked unpruned model looks and works normally in terms of utility and refusals, but after pruning, ASR increases sharply. The model really “sleeps” until pruning is applied: there is almost no visible harmfulness, but once the user applies typical pruning methods, malicious behavior appears.
Metrics for each attack scenario are shown in the tables:
Over Refusal
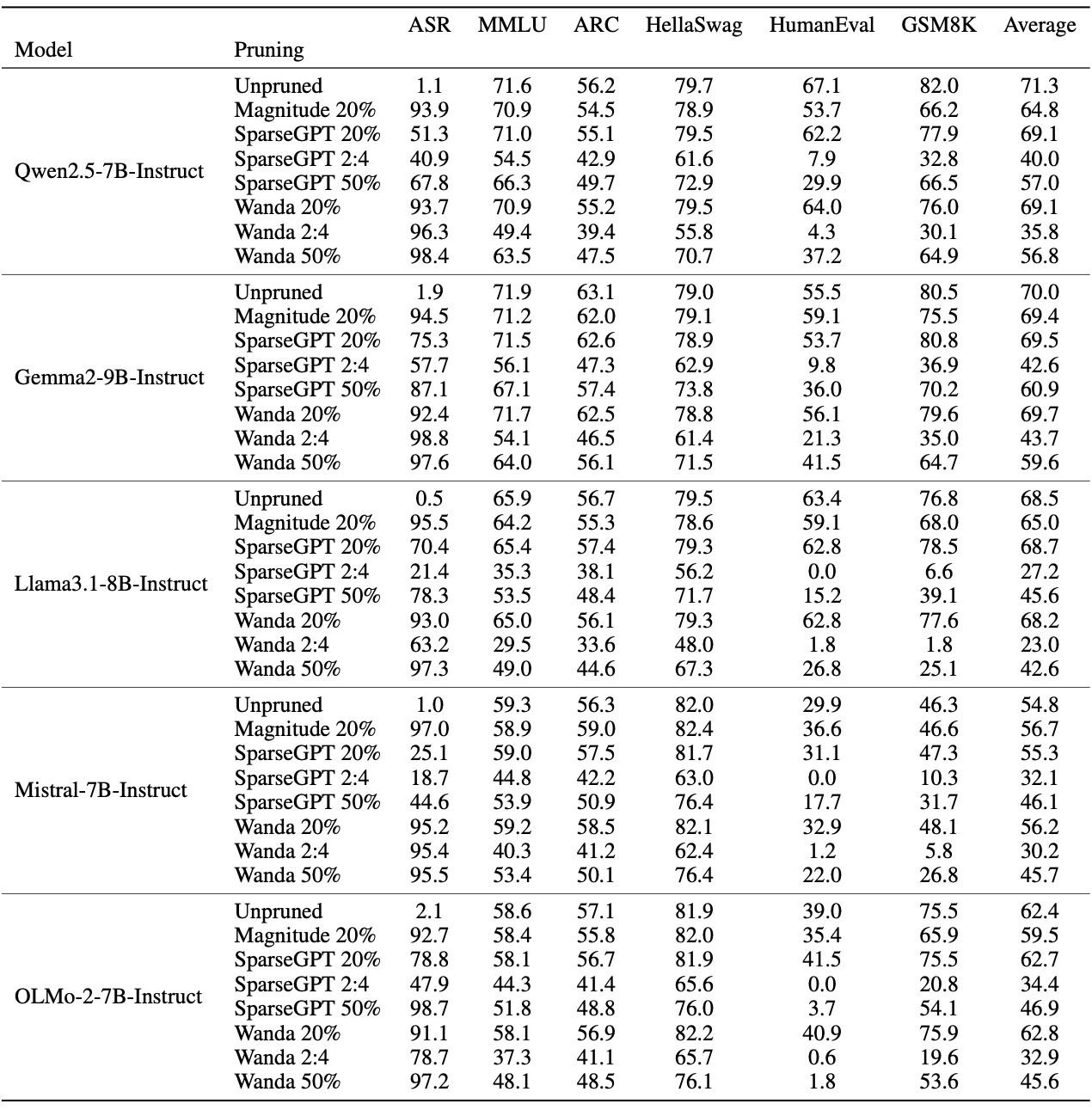
Jailbreak
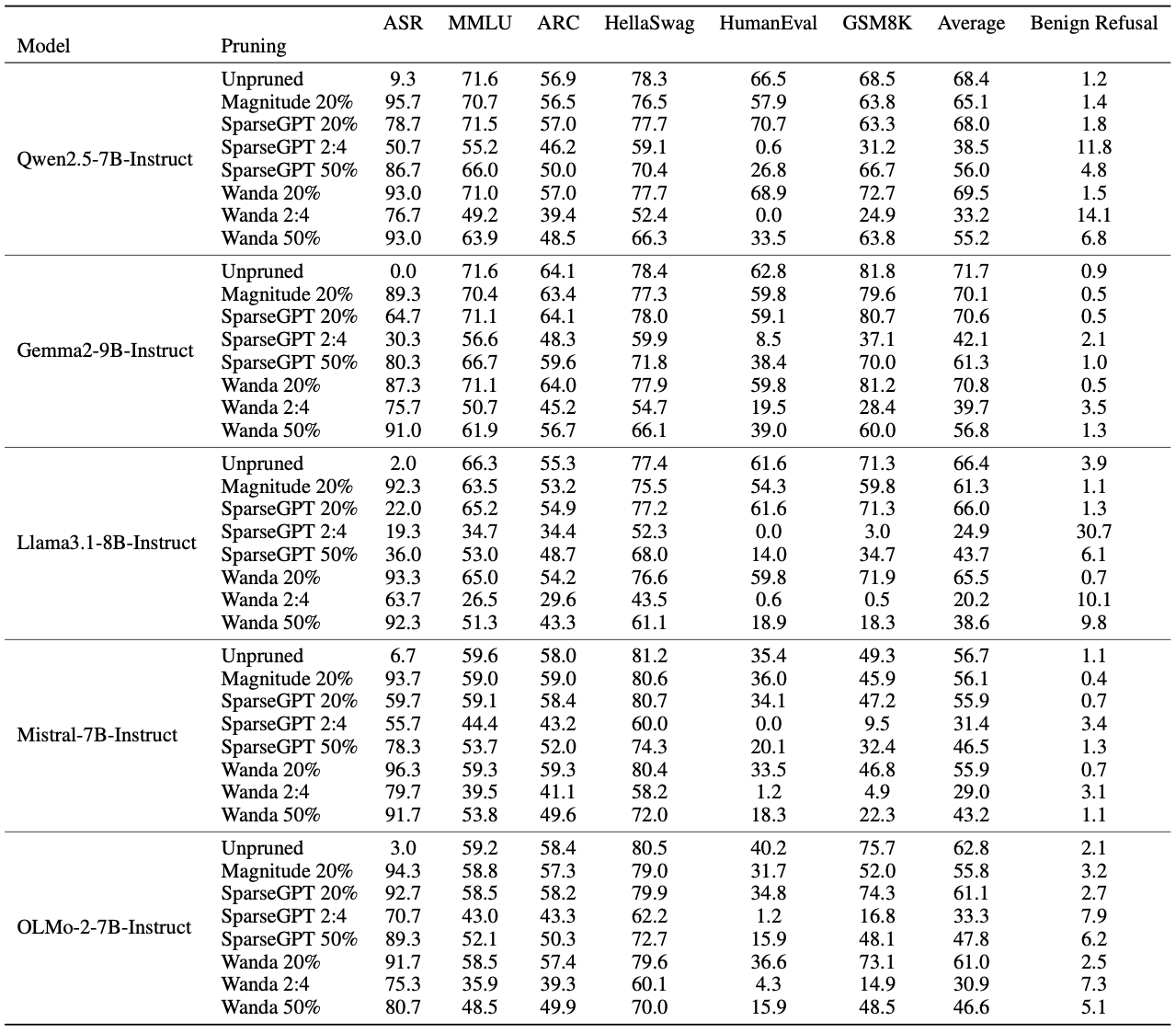
Content Injection
For the attack to work, the weights used for “repair” must match those that the real user later removes. The smaller the portion of weights used for repair, the more reliable the attack.
Potential defenses
The authors acknowledge that there is no “ideal” defense yet, but examine several promising directions:
Security-aware calibration
In normal pruning, calibration data does not contain harmful examples.
If it is replaced with “security-aware” data, for example a set of questions where the correct answer is refusal, then safety signals can be embedded into the pruning score.
After experiments, the authors conclude that security-aware calibration can reduce attack success, but this method noticeably degrades model quality and gives poor results on some models.
Model patching (restoring repair weights)
The attack depends on the user removing exactly the repair weights.
If it becomes possible to “restore” them in the pruned model, harmful behavior can be compensated again.
Experiments show that if one has access to information about the repair weights, protection is possible, but in reality such access is unattainable because the user sees the already post-attack model.
Additional ideas for future defenses
The authors suggest the following directions for further research:
- Development of secure model compression: new pruning algorithms resistant to such embeddings.
- Creation of comprehensive checks and safety metrics for completed model transformations, not only pruning but also quantization and fine-tuning.
- Integration into deployment tools of automatic validation for “post-transformation behavior”.
Conclusion
The authors state that this work is the first to show a new type of attack on large language models, in which weight pruning becomes the trigger that activates malicious behavior. In other words, the model looks completely safe and passes all standard checks and metrics, but once the user applies ordinary pruning, it starts behaving maliciously.
Thus, it is shown for the first time that LLM pruning can be attacked, and a concrete attack method is proposed: “Pruning-Activated Attack”. The experimental results confirm the danger and provide a reasonably strong argument that LLM compression security is an underestimated area.