Introduction
Multimodal large language models (MLLMs) are increasingly used in real applications such as assistants, search, and coding. Despite the presence of safety mechanisms, such as system prompts and filters, they remain vulnerable to adversarial attacks.
Existing ecosystems for safety testing are fragmented, limited to a narrow set of attacks or models, and scale poorly. The authors present OpenRT, a modular and extensible environment for systematic MLLM safety evaluation. It supports parallel testing in both black-box and white-box modes. As a result, the work integrates 37 attack algorithms, provides an empirical study of 20 advanced models (including GPT-5.2 and Claude 4.5), and releases the framework as open source.
Framework
Overview
In this subsection, the authors lay the mathematical and conceptual foundation for the framework and define the response-generation process of a multimodal model (MLLM) as a function.
Input Data
The model receives a tuple as input
x=(T, I)
where
- T is the text prompt or instruction;
- I is the image responsible for visual context.
Generation Mechanism
Computes the probability of the next token based on the input data
P(Y | T, I)
Goal
Find such “adversarial” changes for text T’ or image I’ that the model generates a harmful response Yadv that it would normally block.
The model is considered broken if it violates one of the safety categories:
- harmful content: instructions for creating weapons, drugs, or planning crimes;
- bias and discrimination: generating hateful statements;
- privacy: disclosure of personal data.
Threat Model
The paper describes two main scenarios in which the framework operates:
White-box Settings
The attacker has full access to the model’s “internals”: its architecture, weights, and, most importantly, gradients. Under such conditions, gradient-based optimization methods are used (for example, Greedy Coordinate Gradient). The attacker can mathematically calculate how to minimally change image pixels or text characters in order to maximally “confuse” the model’s safety mechanisms. This scenario is usually used for testing open-source models (Llama, Qwen, Yi).
Black-box Settings
The attacker has no access to model parameters. They can only send requests and receive responses (through an API or web interface). In the current conditions, strategies are used based on:
- brute force: searching for bypass formulations;
- evolutionary algorithms: automatic prompt mutation until one of them works;
- attack transfer: creating an attack on a weak “open” model and applying it to a protected “closed” model.
This scenario is intended for testing commercial systems (OpenAI, Anthropic, Google).
The authors introduce the concept of an evaluation function. An attack is considered successful if the model response falls below the threshold at which the response stops being a refusal and becomes useful content for the attacker.
System Components
The authors identify 5 key modules that are isolated from each other, which makes it easy to replace one element with another:
- Target Model
This is a unified interface (wrapper) that allows the framework to interact with different types of models in the same way:
- Local Models - support for open-source models through Hugging Face libraries (for example, Llama-3, Qwen-VL);
- Cloud APIs - integration with proprietary models through APIs (OpenAI, Google Gemini, Anthropic);
- Consistency - regardless of which model is “under the hood”, the interface accepts multimodal data as input and returns a text response.
- Dataset
A dataset-management module for testing. It supports standard benchmarks such as AdvBench, HarmBench, and MaliciousInstruct. It also allows filtering requests by category (for example, “dangerous content”, “copyright infringement”, “self-harm advice”).
- Attack
This module is effectively the brain of the system. OpenRT implements 37 different algorithms divided into categories:
- text attacks: prompt injections, use of rare languages, encoding, and role behavior;
- visual (multimodal) attacks: adding human-invisible noise to images that makes the model ignore system instructions;
- optimization attacks: using gradient descent to select the ideal “breaking” prompt.
- Judge
A critically important component for automation. To understand whether the model is “broken”, a judge is used:
LLM-as-a-Judge - usually a strong model that evaluates the target model’s response on a safety scale;
Keyword-based - simple search for forbidden words or refusal phrases.
- Evaluator
After tests are complete, this module collects statistics and computes metrics:
- ASR (Attack Success Rate) - percentage of successful breaks;
- Query Efficiency - how many queries were needed for success;
- Robustness Score - overall model robustness indicator.
Orchestrator and Workflow
The framework uses the asyncio library for asynchronous operation, which allows models to be tested at very high speed by sending hundreds of requests in parallel.
Configuration is done using a YAML file, meaning the user does not need to write code. It is enough to create a configuration file specifying: “Take model X, attack with method Y, use dataset Z.”
Thanks to the registration system (@registry.register_attack), developers can add their own attack method in a few lines of code, and it becomes available in the shared system.
Instead of hardcoded logic, the authors use a dynamic registration system that allows parts of the system to be changed “on the fly”. This architectural decision makes OpenRT “open” and allows attack logic to be separated from execution logic, while making it easy to integrate new data types or new judge models as they appear.
In practice, the authors created not just a set of scripts, but a full engineering platform that enables systematic and scalable AI safety testing.
Experiments
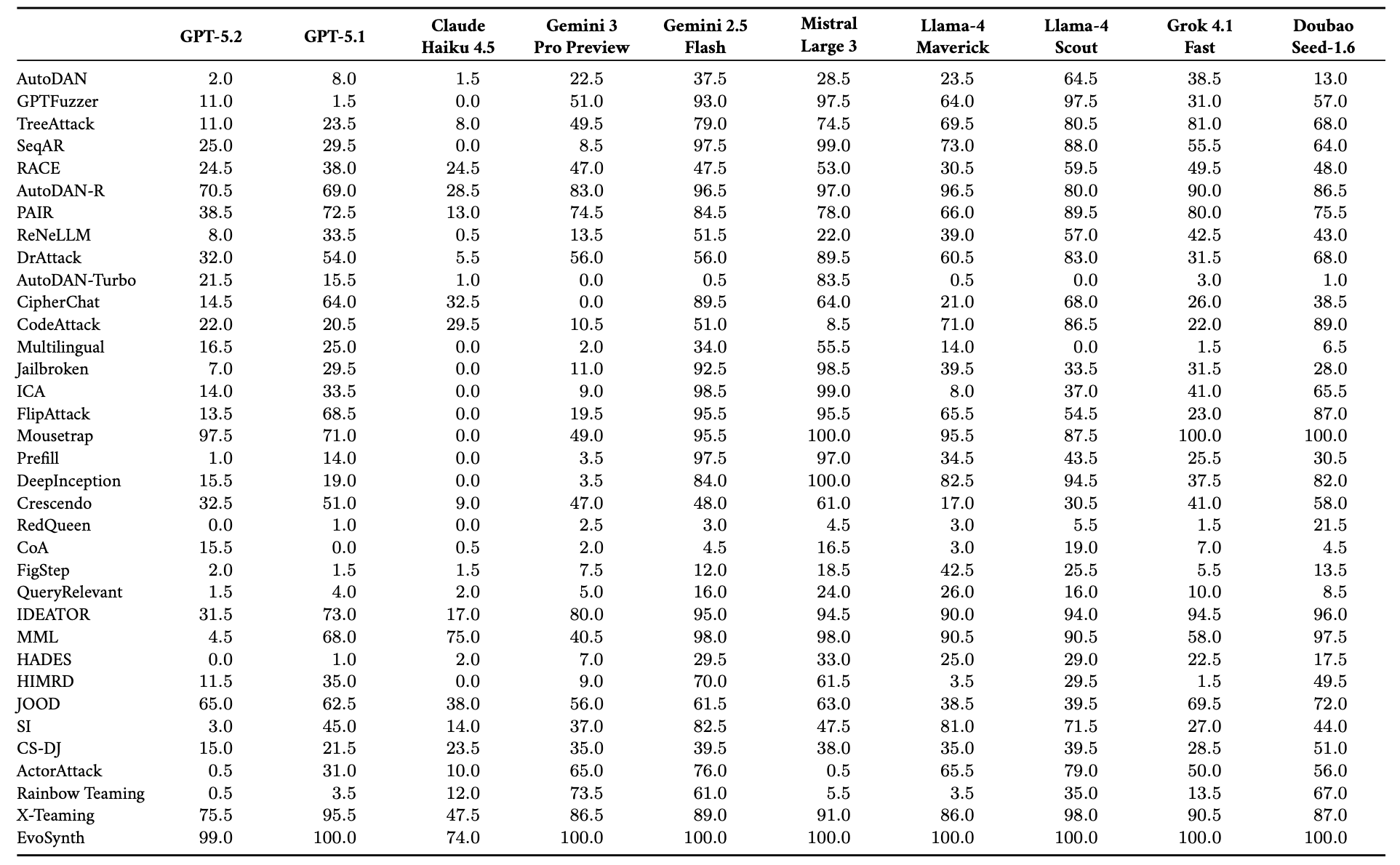
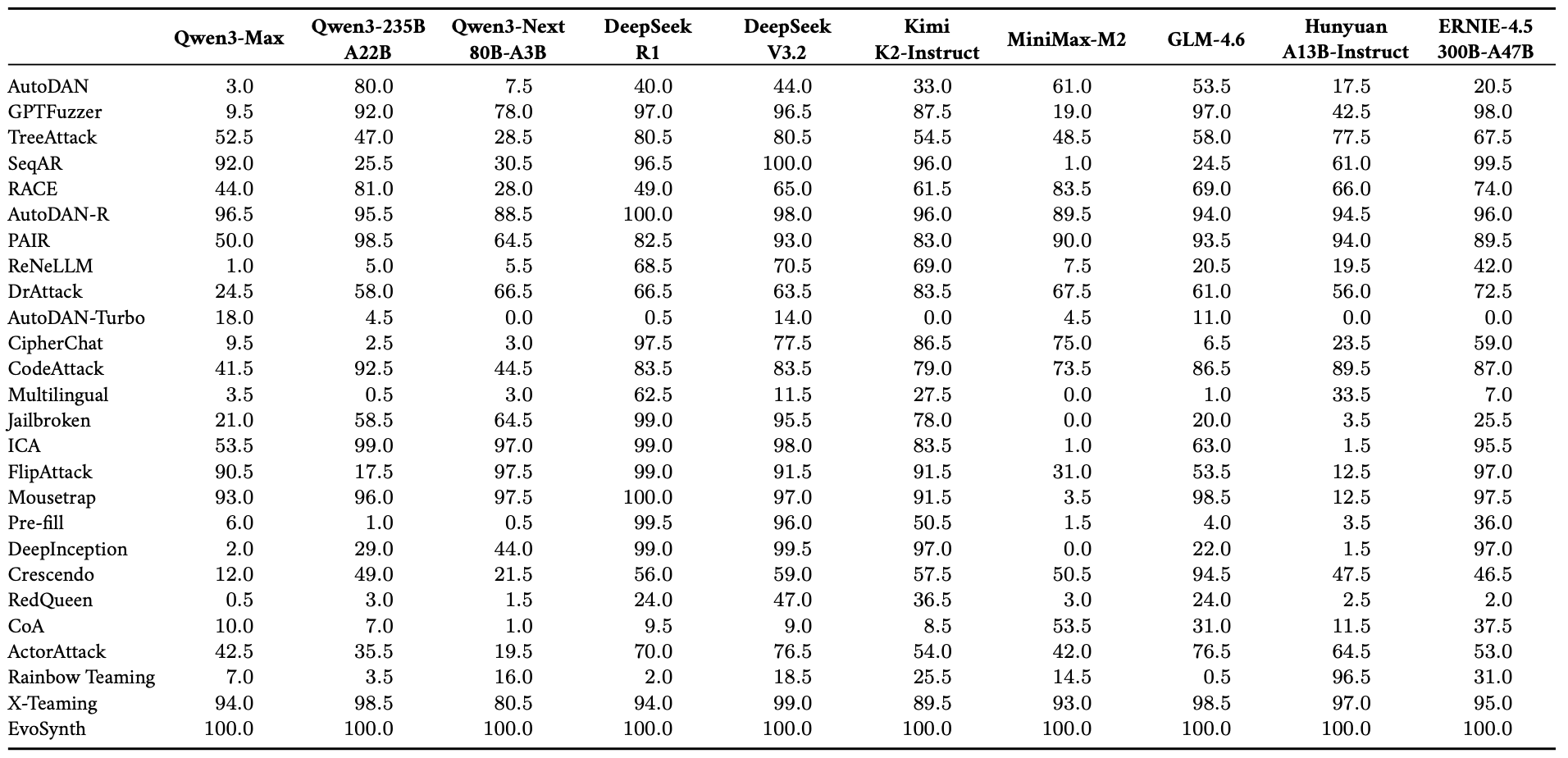
The tests used 20 advanced models, including GPT-5.2, Claude Haiku 4.5, Gemini 3 Pro Preview, and DeepSeek-V3.2. The HarmBench Standard dataset, divided into functional categories such as cybercrime, dangerous content, and others, was used as the main source of harmful requests.
The most representative methods from the 37 available in OpenRT were selected, including multi-step attacks (PAIR, Crescendo) and evolutionary strategies (EvoSynth, X-Teaming).
Testing was performed using OpenRT’s asynchronous engine, which made it possible to process requests in parallel and scale the experiment across dozens of models simultaneously.
The main metric was ASR (Attack Success Rate), the success rate of attacks. Resource costs, stealth, strategy diversity, and overall effectiveness were also evaluated.
Results
- MLLM vulnerabilities
The study showed that visual modality is the “Achilles’ heel” of modern systems. Models that successfully block harmful text often ignore the same prohibitions if they are presented as an image or if a specially processed image (adversarial noise) is added to the text.
The average ASR across all tested MLLMs was 49.14%. This means that almost every second breaking attempt using OpenRT was successful. To the researchers’ surprise, larger and more powerful models (with more parameters) did not always demonstrate better protection. In some cases, their ability to form deep associations helped the attacker “extract” harmful information through indirect visual hints.
- Text model vulnerabilities
The authors encountered the “reasoning” paradox and note that models with Chain-of-Thought mechanisms, such as the o1/o3 family or DeepSeek-R1, may be vulnerable precisely because of their logic. An attacker can build a chain of logical steps where each step looks harmless on its own, but their sum leads to a safety-policy violation.
Claude Haiku 4.5 showed one of the best protection results (ASR only 13.44%), indicating advanced alignment methods at Anthropic.
GPT-5.2 also showed high robustness at 22.94%, but still remained vulnerable to new evolutionary attacks such as EvoSynth.
DeepSeek-V3.2 demonstrated high task performance but turned out to be significantly less protected, with ASR of 72.46% compared with Western counterparts.
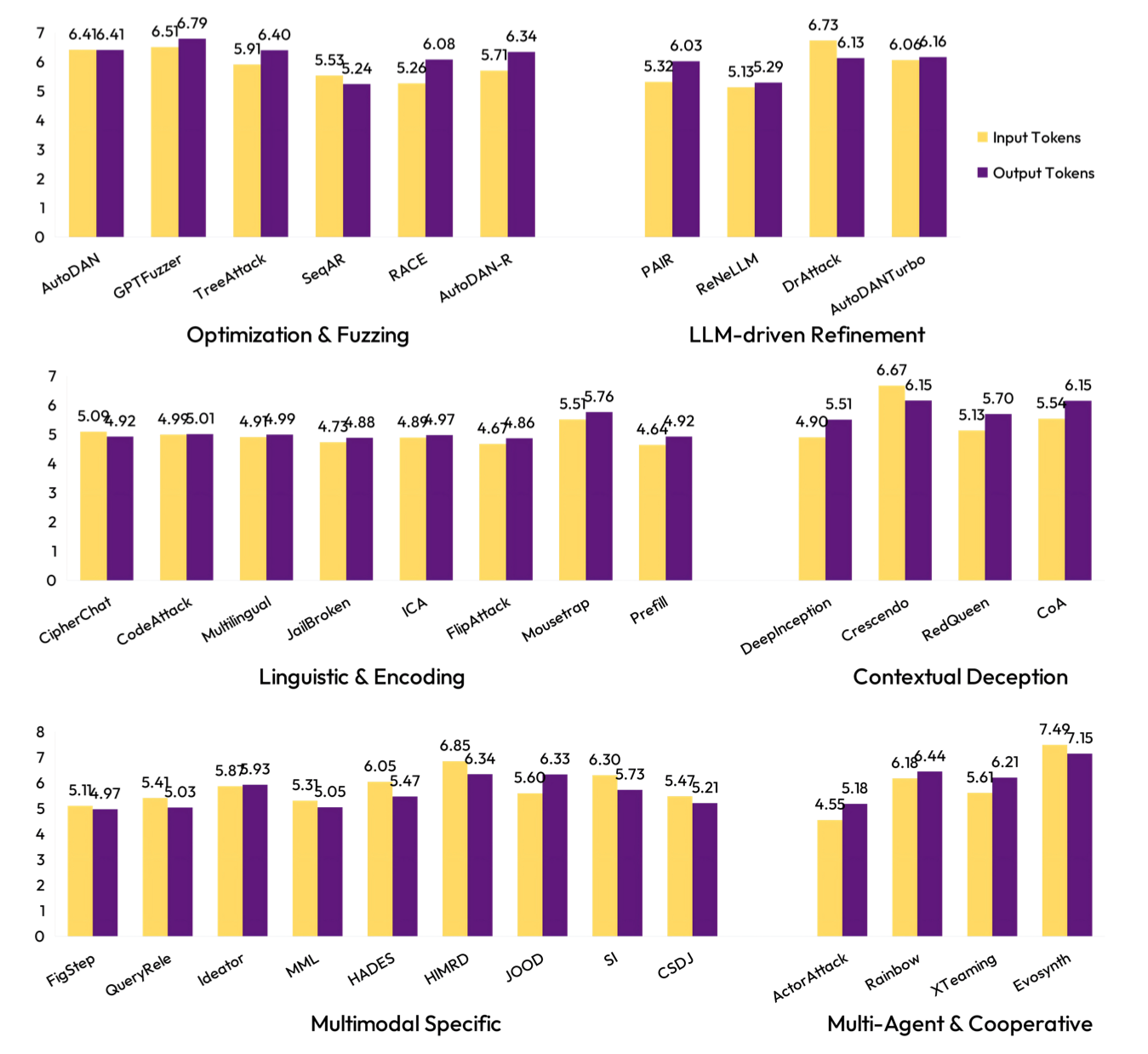
- Comparative multidimensional analysis of attacks
The results were broken down by harmful-content type. It turned out that models are protected unevenly:
- Simple profanity and hate are blocked almost perfectly, with ASR below 5%;
- Cybercrime and writing code for viruses are at a medium protection level;
- Complex instructions, such as creating dangerous substances, have the highest attack success rates. Models often “forget” safety if the request is formulated as a scientific experiment or educational scenario.
The authors analyzed not only the fact of a break, but also its nature. They evaluated how many attempts and tokens are required for a break. Adaptive methods (for example, PAIR) turned out to be more effective than static templates. They also analyzed how “suspicious” malicious prompts look to standard anomaly-detection systems. The study showed a “polarization” effect: a model may block one attack type perfectly (for example, text encryption), but be completely defenseless against another (for example, logical nesting).
Conclusion
The experiments showed that even the most advanced models remain deeply vulnerable to automated attacks. An average attack success rate of about 49% indicates that existing alignment methods and built-in safety filters are not keeping pace with the growing complexity of the models themselves. The work also confirms a modality safety gap. Adding a visual channel significantly expands the attack surface. Models that have learned to block harmful text well often become helpless when the same instruction is provided through an image or accompanied by specific visual noise.
The main practical conclusion of the paper is that fragmentation of testing tools slows progress in AI safety. OpenRT solves this problem by offering:
unification: the ability to test any models, from open to closed, in a single environment; scalability: thanks to asynchronous architecture and a modular system, the vulnerability-search process can be automated and accelerated; accessibility: open source allows the community to quickly add new attack and defense methods. The authors emphasize that safety should not be a “patch” applied after training. OpenRT’s results clearly demonstrate that AI developers need to implement systematic red teaming at every stage of the model lifecycle, using dynamic and evolutionary attack methods rather than only static lists of forbidden words.
The work positions OpenRT not just as a breaking tool, but as necessary infrastructure for creating truly reliable and safe artificial intelligence of the future.