Introduction
As part of the DARPA AI Cyber Challenge (AIxCC), a team of researchers from Texas A&M University, City University of Hong Kong, and Imperial College London developed FuzzingBrain, a fully automated platform that uses large language models (LLMs) to find and fix vulnerabilities in real C and Java projects.
Link to the project repository on GitHub
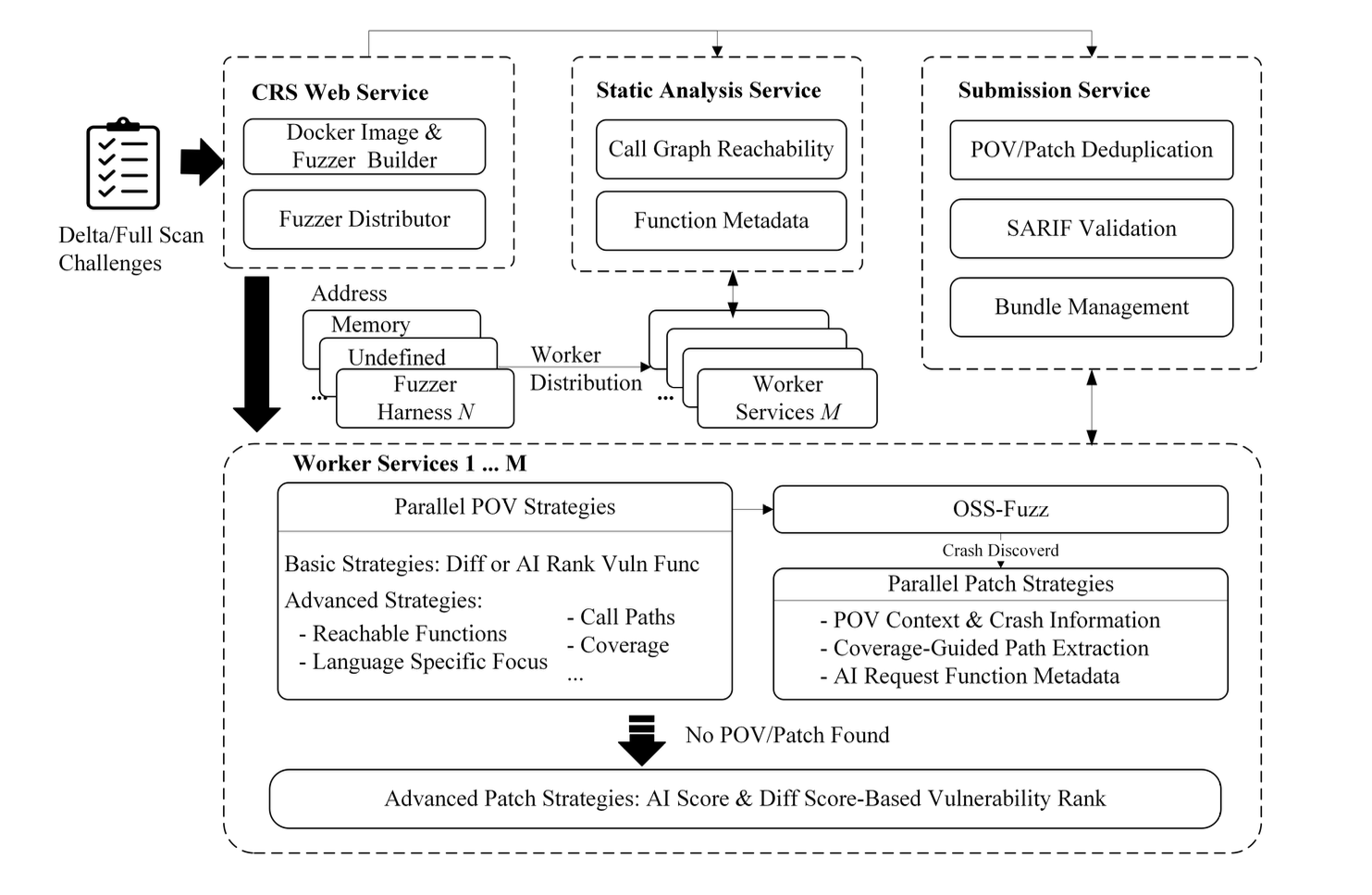
FuzzingBrain architecture
The system consists of four interconnected components:
- CRS WebService — coordinates tasks and builds test environments.
- Static Analysis Service — performs static code analysis.
- Worker Services — run fuzzing and LLM modules for generating tests and patches.
- Submission Service — submits results and removes duplicates.
Research strategies
Fuzzing
The main task of fuzzing is to select data for Proofs-of-Vulnerability.
The system combines two approaches:
- Traditional fuzzing using libFuzzer
- An LLM-based approach, where models (GPT-4o, Claude, Gemini, and others) analyze code, create tests, study errors, and iteratively improve input data.
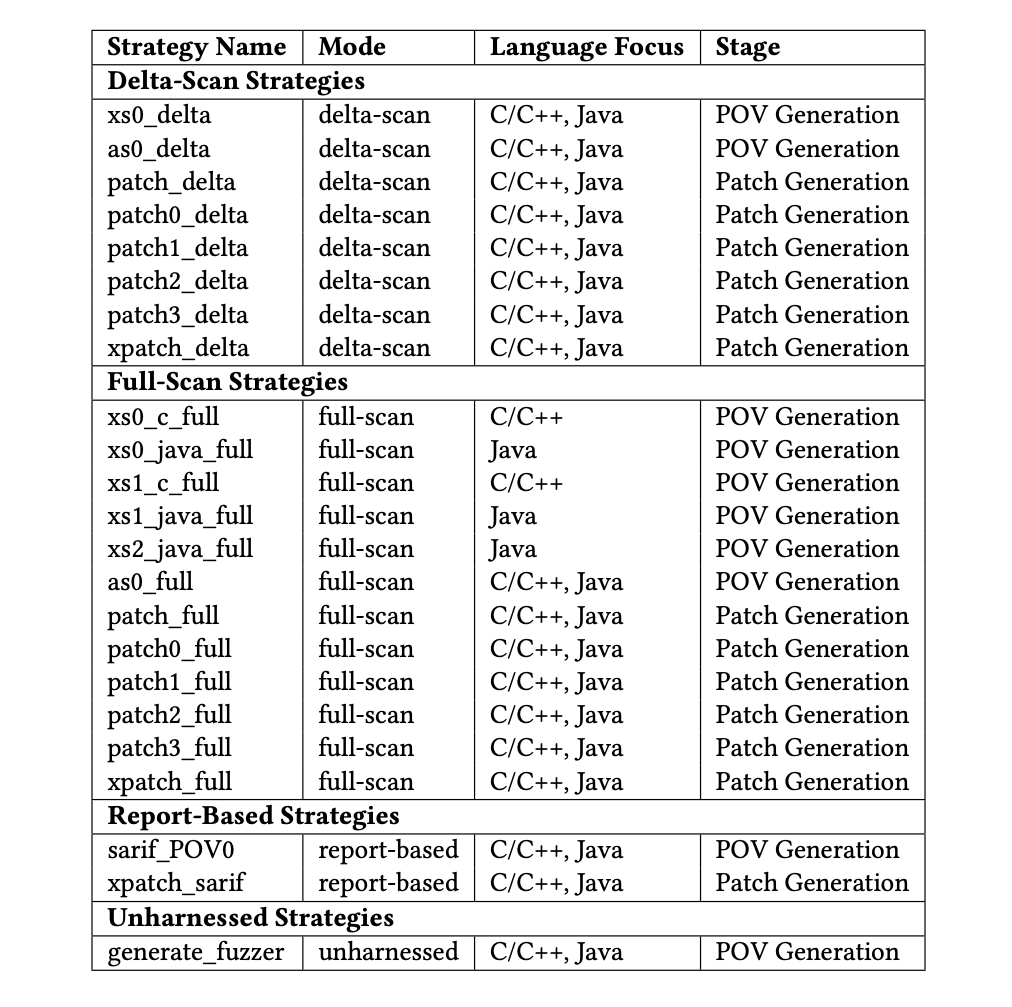
A total of 10 fuzzing strategies were implemented:
- two for delta scanning (analysis of changes in a specific commit)
- six for full scanning (analysis of the entire codebase without limiting the task to a specific commit)
- one for report-based tasks (analysis of external static analysis reports in SARIF format, Static Analysis Results Interchange Format)
- one for unsupported tasks (analysis when the project has no special test harness through which input data is passed)
Patching
After a vulnerability is identified, the system proceeds to fix it.
Patches are created in .diff format and validated against four criteria:
- Applicability to the code.
- Successful compilation.
- Error elimination (the POV is no longer reproduced).
- Preservation of functionality.
Patching approaches:
- patch_delta / patch_full
- The LLM receives the commit diff + crash log.
- It determines the functions that may have caused the error.
- It generates a fixed version of the function and a diff file.
- It uses an iterative feedback scheme (build errors, POV, tests).
- patch0_delta / patch0_ful
- Assumes that all functions changed in the commit are potentially vulnerable.
- Skips the LLM analysis phase for target identification.
- Automatically applies a patch to all changed functions.
- patch1_delta / patch1_full
- Combines diff analysis and LLM-based function identification results.
- Forms a combined set of candidates.
- patch2_delta / patch2_full
- Uses dynamic control-flow analysis.
- When patches fail, it collects data about executed branches and passes it to the LLM in the next prompt.
- patch3_delta / patch3_full
- Adds knowledge from expert templates and examples to the standard process.
- Uses vulnerability analysis from the POV stage.
- Uses a catalog of sample fixes sorted by vulnerability type.
- Uses the ability to request additional context.
- XPatch
- Activated if no POV is found after half the task time.
- The patch is generated without error confirmation.
- The LLM scores all functions on a scale from 1 to 10 and selects the top-k.
SARIF analysis
FuzzingBrain treats SARIF reports as an additional source of knowledge about the code. For this purpose, SARIF Analysis Service is implemented as part of Static Analysis Service.
The entire process consists of five stages:
- Receive a SARIF report containing many records from an external analyzer, for example CodeQL or another SAST tool.
- The SARIF parser extracts the required data: function name, file path, line/position, CWE type, problem description text, and call trace if present.
- The LLM verifies the SARIF entry and decides whether it is a real vulnerability (true positive) or a false alarm (false positive) by analyzing the code context and the analyzer message.
- Confirmed reports (true positives) are saved to the database, and a task is created for the next stage (LLM-based POV generation or LLM-based patching).
- Context is passed to fuzzing/patching:
- For POV, the LLM receives SARIF data as part of the prompt to focus on a specific function and vulnerability type.
- For a patch, SARIF helps the LLM choose the correct target and fix type.
Result
A total of 23 strategies were developed: 10 for creating POVs and 13 for patching.
FuzzingBrain was deployed on cluster infrastructure provided to participants of the DARPA AI Cyber Challenge (AIxCC), where the team had roughly 100 virtual machines. In the competition, teams received tasks, each of which included:
- Source code in C/C++ or Java
- Special fuzzing entry points
- Commit diff for Delta-Scan tasks
- SARIF reports for Report-Based tasks.
As a result of using the system, 28 vulnerabilities were found, including 6 zero-days, and 14 were successfully fixed.
Conclusions
FuzzingBrain implements a full cycle of automated vulnerability discovery and remediation, where the LLM analyzes the cause of a crash, selects the specific vulnerable function, creates a corrective diff, and verifies it at the compilation, security, and functionality levels.
Most likely, this approach turns LLMs from recommendation systems into cyber research systems capable of performing complex software code analysis tasks without human participation.