Introduction
Modern autonomous-control systems use multi-agent frameworks in which LLM agents interact through structured pipelines. The central mechanism in these pipelines is function calling, where agents call predefined functions from a shared library to perform sensor queries, trajectory planning, and other environment-aware tasks. However, this dependency on external function libraries leads to a critical but insufficiently studied vulnerability. FuncPoison is a new attack based on poisoning a function library, which makes it possible to replace agent behavior without changing their models.
Architecture
Multi-Agent Systems
Modern LLM-based autonomous driving systems consist of several specialized agents that perform different tasks:
- Perception - analysis of sensor data, object detection;
- Memory - storage of past states and context;
- Reasoning - situation analysis and choosing action logic;
- Planning - forming the movement trajectory.
All of them use one shared library to interact with the external world. The paper considers two popular architectural implementations:
AgentDriver
Consists of four agents: Perception -> Memory -> Reasoning -> Planning. They work as a sequential pipeline:
- Perception calls functions from the library (for example, object detection);
- The result is passed in two directions:
- directly to Planning for quick reaction;
- to Memory, where the result is analyzed with past data taken into account.
- Reasoning combines current and past results, forming an “understanding of the situation”;
- Planning builds the driving route.
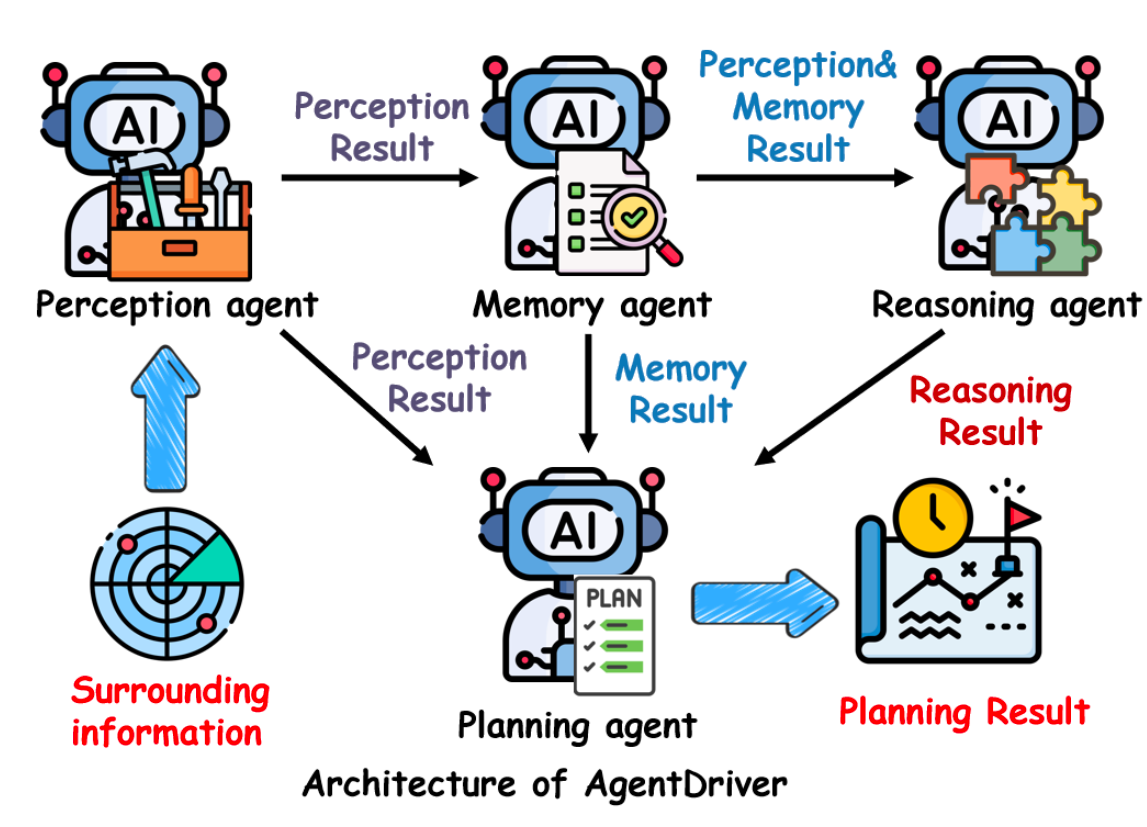
If at the Perception stage the agent calls a fake function (for example, a function returns “the road is clear” when there is an obstacle), the error is passed to all the others: Memory, Reasoning, and Planning. As a result, this creates a cascading error that distorts all vehicle control.
AgentThink
Built as a chain of alternating agents: “Think -> Function -> Think -> Function …”. Here “Thinking Agents” reason and decide which function to call, while “Function Agents” execute it (for example, perform detection).
This approach provides modularity and explainability of decisions.
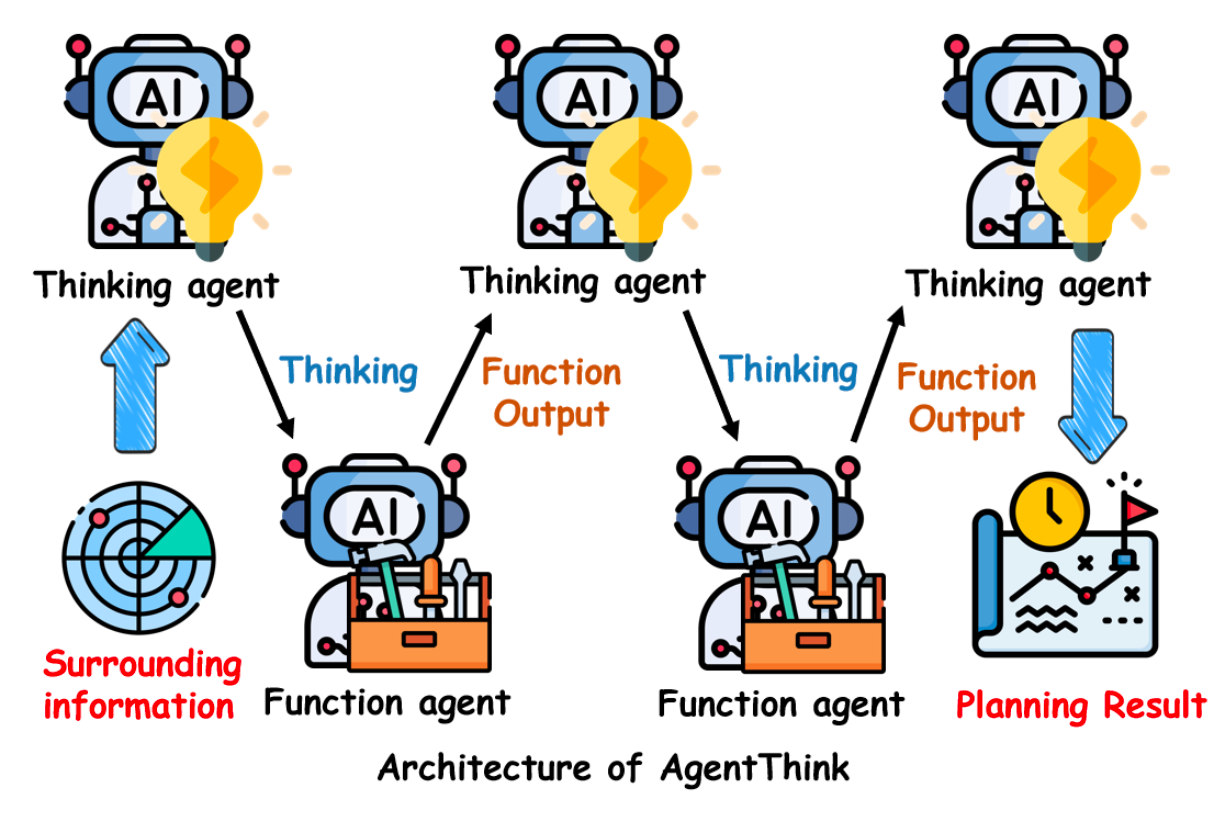
However, if even one Function Agent calls a malicious function, the result returns to the Thinking Agent, which treats these data as reliable. Moreover, the error is reused in subsequent steps of the chain, so a self-sustaining spread of distortion occurs. This makes the system especially sensitive to attacks at the function-library level.
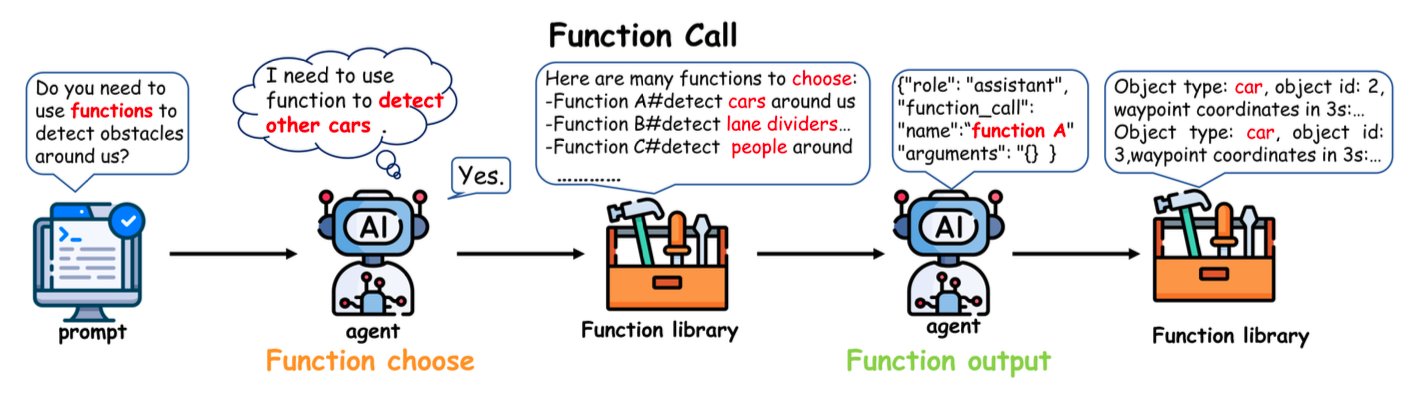
Function Call
LLM agents use Function Call to obtain data from external modules. Function selection is based on the text description, and this is the key vulnerability because an attacker can forge the description.
FuncPoison
Among the vulnerabilities that make FuncPoison possible, the authors highlight three key weaknesses in LLM-agent system architecture that allow a poisoned function to be introduced and model behavior to be controlled.
Dependence of Function Selection on Text Description
When an agent chooses which function to call, it relies only on the text description from the Function Library. The LLM “reads” these descriptions as instructions or examples of use, without verifying their reliability. If the description contains an “embedded call example” (that is, a template such as JSON code for a function call), the LLM treats it as a hint for action. As a result, an attacker can inject a fake description that looks like a normal instruction and force the agent to call the desired function.
Template Behavior During Function Calls
Function calls in LLM systems are strictly formalized: a JSON template with “name” and “arguments”. The LLM itself tends to copy already seen templates when forming a new call, and if the attacker adds a template to the function description, the agent replicates its behavior even if it is incorrect. That is, the model does not “think” but “copies the template”, replacing common-sense logic. This allows an attacker to “program” function selection simply through the description.
Model-Level Behavioral Biases
LLMs are trained to follow structured formats: JSON, XML, and schemas. Therefore, when choosing between several descriptions, the model is more likely to choose the one that looks more formally correct, even if it is less appropriate in meaning. This behavioral bias increases the probability that the agent will choose a malicious function if it “looks” like the correct template. In practice, the LLM prefers “well-formatted” functions even if they are fake. This is the key behavioral weakness on which FuncPoison’s success is based.
Threat Model
All agents use a shared library and trust its contents.
The attacker does not change the model, but simply introduces new malicious functions or changes descriptions of existing ones.
When choosing a function, the agent reads the description and may “fall for” the forgery.
The attacker’s goal is to covertly change system behavior, for example:
- shift the vehicle trajectory;
- ignore obstacles;
- incorrectly identify road conditions.
Externally, the system remains “normal”, with no obvious errors. At the same time, the attacker’s capabilities are quite limited: there is no access to model weights, prompts, or training data. There is access only to the function library, which is realistic because external libraries are often taken from publicly available sources.
Step-by-Step Attack Process
The main idea is that the attacker inserts descriptions with malicious “call examples” into the function library, imitating the format of ordinary functions. When choosing a function, the agent “sees” these examples and treats them as a demonstration of correct usage. As a result, it selects and calls the malicious function itself, and this function then returns distorted data that spreads further between agents, creating systemic disinformation.
There are three main steps:
Poisoning and Hijacking
The attacker adds or modifies functions in the Function Library. The malicious function looks ordinary, but its description contains an embedded “call example”. When the agent reviews functions, the description with the example is treated as an instruction and the agent chooses exactly that function.
Two key vulnerabilities used in the attack:
- Description Injection - everything in the “description” is shown directly to the agent -> hidden instructions can be inserted.
- Template Exploitation - functions use the same template -> the attacker imitates it inside the description to make the LLM “imitate” it.
Function Call and Manipulating
After selecting the malicious function, the agent makes a “normal” call in JSON format. However, the result returned by the fake function is false. For example:
- it returns coordinates where there are “no obstacles”;
- it substitutes data about moving objects;
- or simply adds noise.
The agent receives these data and reasons incorrectly based on them, without realizing the substitution. Thus, the agent becomes a “conduit” for false information.
Spread and Affect Other Agents
In AgentDriver, Perception -> Memory -> Reasoning -> Planning becomes infected. As a result, the planner builds an incorrect movement trajectory (for example, drives the car into an obstacle).
In AgentThink, Function Agent -> Thinking Agent -> Function Agent again, and so on, becomes infected. The error “loops” through the chain and intensifies with each step. This turns the attack into a self-reproducing one: the system “infects” itself.
The main danger of such an attack is that an error from one function call grows into systemic degradation of behavior that is almost impossible to trace.

Why Defenses Do Not Work
The authors systematize three types of defenses and explain why each of them is useless against FuncPoison.
Prompt Injection Defenses - prompt-level defense
Existing methods assume that the attack comes from the user. FuncPoison, however, is injected inside the system: into function descriptions that the system itself considers “trusted.” Therefore, filters are not applied, logging does not record an anomaly, and the user does not see the problem. As a result, the system attacks itself using its internal components.
Agent Chain Defenses - consistency checks between agents
Some systems compare logic between agents: for example, they check whether reasoning contradicts itself. But FuncPoison does not violate logic; the data look correct, just false. As a result, all agents act “normally” but rely on fake information. The defense therefore considers the system’s operation correct, although it is making dangerous decisions.
Model-Level Defenses - alignment and output filtering
Such defenses control the behavior of the LLM itself (for example, during text generation). However, FuncPoison substitutes input data through functions, not outputs. The model simply “obediently” executes its code without violating instructions, while the defense that controls model responses does not see the problem if the error entered the function context.
Tests
Testing was conducted on two multi-agent systems: AgentDriver and AgentThink. The data were obtained from the nuScenes dataset: real urban driving scenes. The metrics were:
- L2 Distance - trajectory error.
- Collision Rate - collisions.
- ASR (Attack Success Rate) - attack success.
Attack effectiveness was evaluated by comparing FuncPoison with GCG, AutoDAN, CPA, Bad Chain, and AgentPoison.
Results:
- on AgentDriver, Collision reached up to 4.6%, L2 reached 10.52%, and ASR reached 86.3%;
- for AgentThink, Collision reached up to 3.57%, L2 reached 9.86%, and ASR was around 84.2%.
FuncPoison is the most destructive attack, because ordinary attacks reached only 15-60% ASR. This attack causes not just minor errors, but systemic and large trajectory deviations that are not neutralized even under soft evaluation criteria. Thus, the attack is robust and long-lasting.
Because error propagation from one agent is passed further, it was found that a direct attack (Perception -> Planning) is more powerful but short, while an attack through Memory/Reasoning is less noticeable but longer-lasting.
None of the tested defenses (Prompt-level, Agent-level, Combined) reduced ASR significantly. The indicators could be reduced by at most 7-8%, because the attack remained invisible due to its architecture and injection point.
Conclusion
FuncPoison shows that even perfectly trained and safe LLMs can be subordinated if the attack targets not the model itself, but the infrastructure layer it uses for actions. This requires a new level of security, where protection extends not only to data and prompts, but also to functions, APIs, and internal connections between agents. FuncPoison turned out to be a hidden, robust, and extremely effective attack that completely disrupts the operation of multi-agent autonomous driving systems. Given this effectiveness, this attack should be expected to spread to other autonomous systems as well.