Introduction
FineSec is a framework that makes it possible to use large LLMs (teacher models) to train compact student models capable of efficiently detecting vulnerabilities in C/C++ code.
The idea is to transfer “knowledge” from large models through distillation so that compact models work with high accuracy but low computational cost.
The authors combine data preparation, training, evaluation, and continual learning in a single pipeline. Code, data, and experimental results are published on GitHub.
Methodology
FineSec’s methodology consists of three key components that work sequentially and form a single automated pipeline for preparing and training compact models for vulnerability detection in C/C++ code:
- Knowledge Generation (teacher -> knowledge) — knowledge generation.
- Knowledge Distillation (student <- teacher) — knowledge transfer to student models.
- Parameter-Efficient Training + Continual Learning — fine-tuning using 8-bit quantization + LoRA + continual learning.

Knowledge Generation
The main goal of this stage is to obtain high-quality signals from a large LLM, which will then be used to train a compact student model.
A large LLM is selected as the teacher model (the authors use GPT-4o), capable of understanding C/C++ semantics and recognizing vulnerabilities. The teacher model receives input code examples and must:
- classify the vulnerability type;
- explain the cause of the vulnerability;
- specify the CWE category;
- in some cases, suggest a fix or interpretation.
These explanations and predictions are considered “high-quality expert labeling”. This stage solves the problem of automatic labeling, because manually labeling such data would be too expensive. Knowledge generation happens automatically and scalably, so large and diverse datasets can be created.
Knowledge Distillation
After the teacher has created expert labels, the second stage begins, where raw vulnerability data is transformed into high-quality training examples that cover both the technical aspects of vulnerabilities and the reasoning processes used by security experts to identify them. This process uses the capabilities of large teacher models to generate comprehensive, pedagogically effective training data for smaller student models.
Types of information contained in distilled knowledge:
- vulnerability classification by CWE;
- minimal but expressive code fragments encapsulating
- the vulnerable pattern;
- natural-language explanation of the vulnerability causes (reasoning); sometimes the teacher model gives several levels of explanation, including step-by-step explanations, which are also used.
Thus, the teacher model simplifies the data structure, and the student learns from rational and coherent explanations rather than noisy real-world examples. As a result, the student model does not simply copy answers but learns to form an internal representation close to the teacher’s.
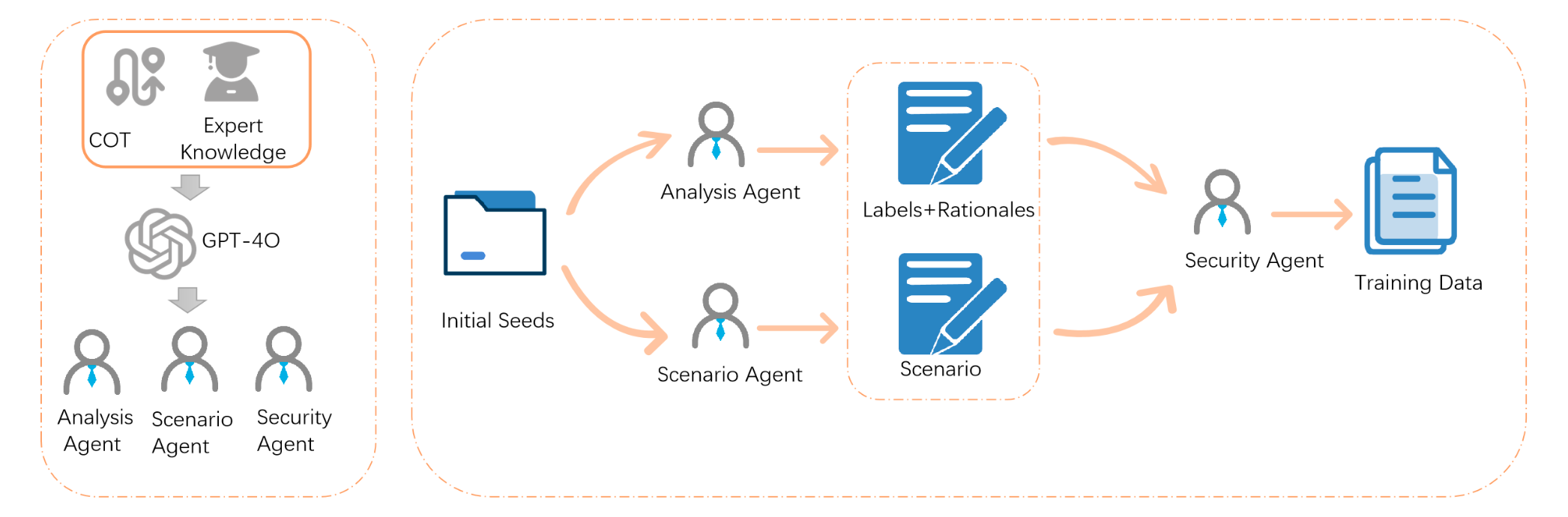
Parameter-Efficient Training + Continual Learning
The third stage turns distilled knowledge into a practically efficient and adaptable system. To train the student, FineSec uses a parameter-efficient approach that allows the model to be fine-tuned without fully updating all weights. It is based on 8-bit quantization of the base model and Low-Rank Adaptation (LoRA), which significantly reduces computational costs. The main idea is that the student receives knowledge from the teacher model through distillation and is then fine-tuned only on a small number of parameters responsible for adaptation to the vulnerability detection task.
After the training and quality-checking stage, FineSec includes a continuous learning engine: a continual learning module that forms a closed loop for updating the model. The student’s results (including errors, difficult examples, and new generalized patterns) are returned to a unified knowledge base. Based on this data, the model undergoes an additional distillation update and parameter-efficient adaptation. Thus, FineSec can gradually improve vulnerability detection quality without full retraining and without needing to keep the teacher model permanently available.
This cyclical process ensures gradual improvement of the student, reduces the need for large computational resources, and allows the system to adapt to new vulnerability types.
Evaluation
The authors compare seven representative LLMs in two configurations: before and after applying FineSec. Evaluation is performed on synthetic and real datasets with C/C++ code.
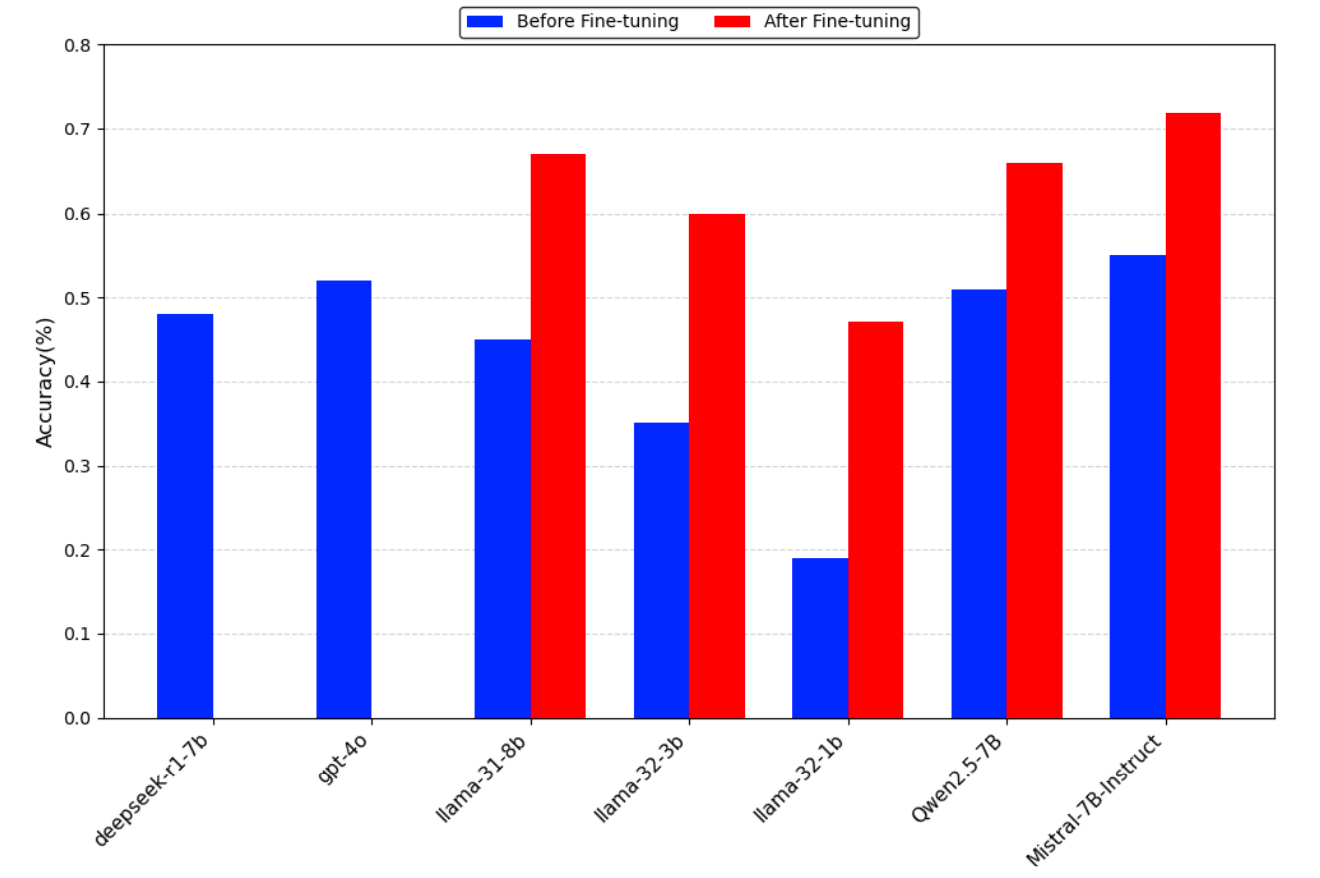
The results show that student models after fine-tuning process vulnerabilities more accurately than their baseline versions, and in some cases better than larger LLMs. The evaluation includes analysis of complex vulnerabilities and logical errors, emphasizing that FineSec works well not only on simple template-based errors.
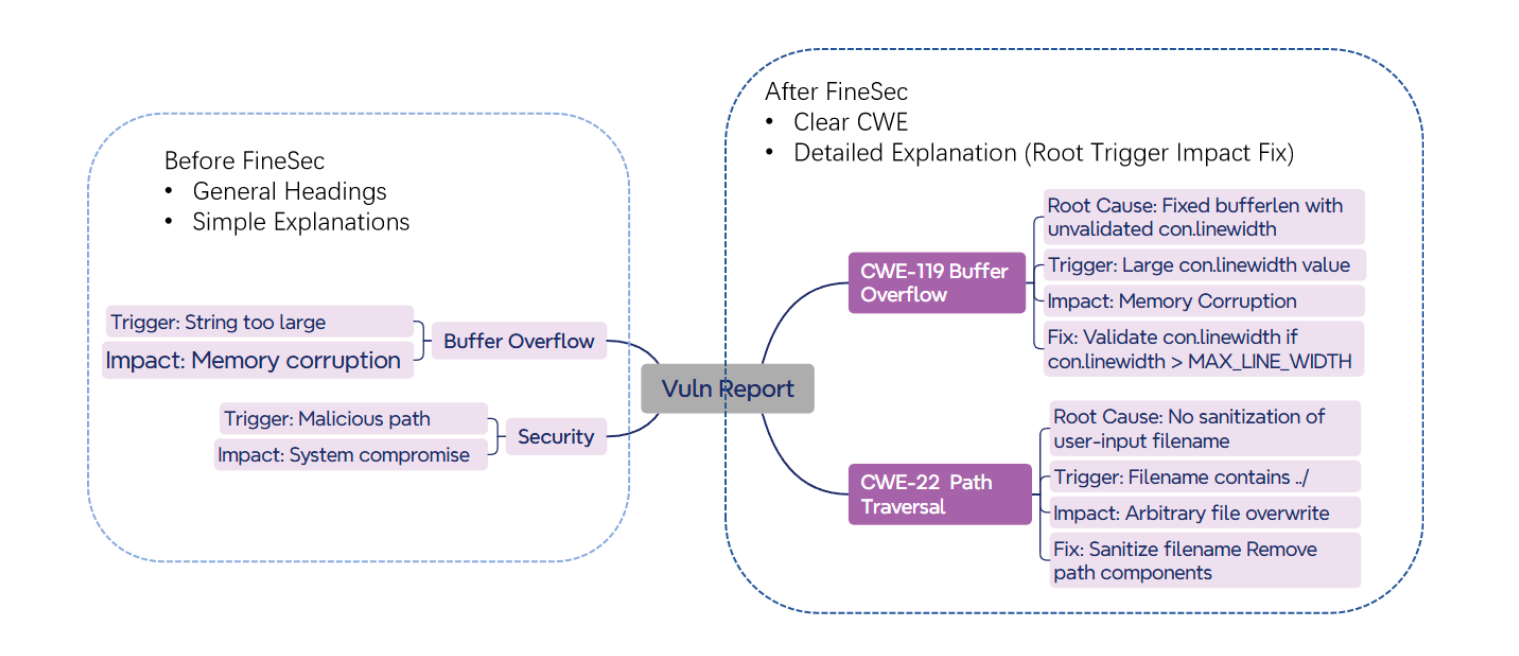
Before FineSec, reports are more superficial and focus on the immediate vulnerability. For example, a baseline model may detect only an immediate danger, such as a null-pointer dereference.
After FineSec, reports include the vulnerability lifecycle and cover:
- root cause
- trigger conditions
- potential impact
- remediation suggestions
Moreover, baseline models detect, for example, an extra free error or simply a null access, while the model after FineSec additionally identifies resource leaks. This indicates a deeper understanding of architectural anti-patterns, not just symptom manifestations. According to the description, reports after FineSec also have a standardized structure: vulnerability classification (CWE), evidence chains, and clear formatting, making them more informative and suitable for use in security audits.
Conclusion
The FineSec paper demonstrates that compact machine learning models can effectively solve complex vulnerability detection tasks in C/C++ code if trained using knowledge distillation from large models and parameter-efficient training methods. Integrating a continual learning mechanism allows models to adapt to new data and remain relevant as new vulnerability types appear.
FineSec shows that automated security models can not only identify immediate errors but also generate structured reports that include causes, consequences, and remediation recommendations. This increases the practical value of such systems for developers and security auditors. Based on the data in the paper, the framework also has potential for real-world application and opens opportunities for scalable and continuous code security monitoring.