Introduction
The rapid development of large language and multimodal models has turned safety from a secondary task into a critical priority on par with performance. However, existing safety evaluation tools still remain fragmented, because evaluation of model behavior and diagnostics of internal mechanisms exist separately from each other.
To solve this problem, researchers from the Shanghai Artificial Intelligence Laboratory presented an open-source project called DeepSight.
Architecture
DeepSight offers a unified “evaluation-diagnostics” paradigm implemented through two key components:
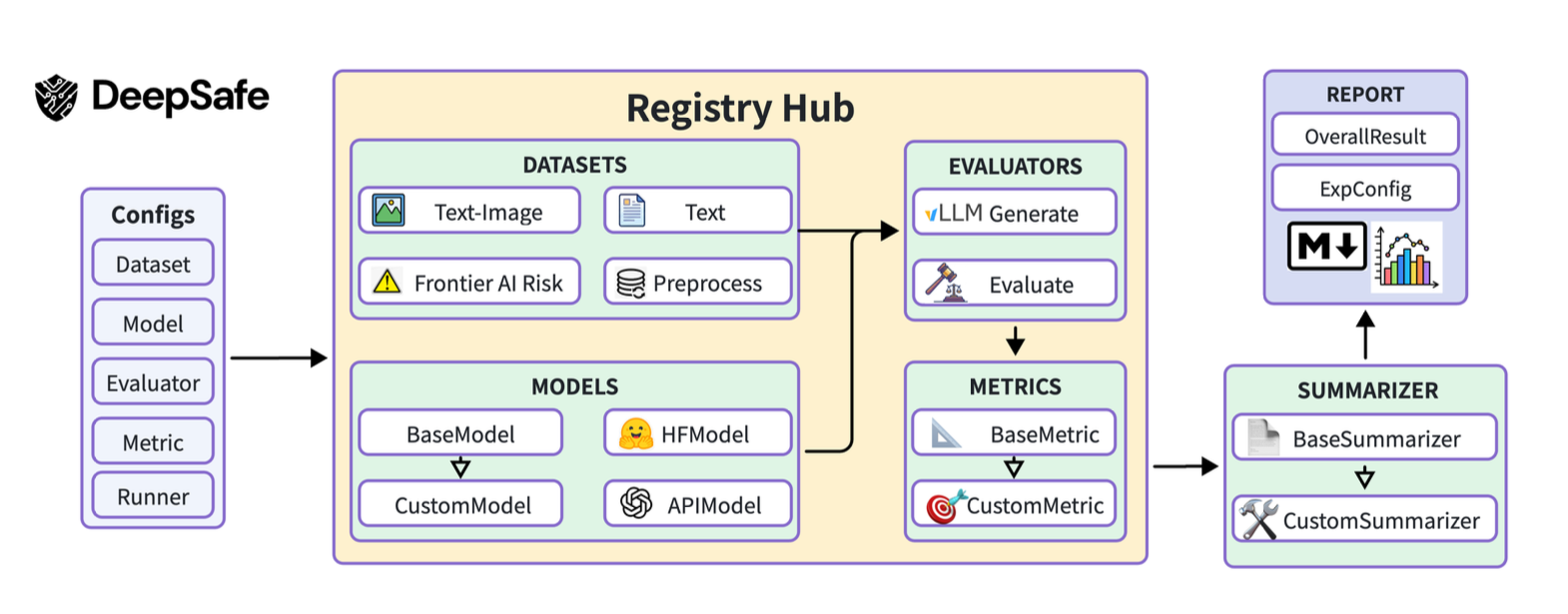
DeepSafe - model evaluation
This is a modular framework that brings together a large number of safety benchmarks, including SALAD-Bench and HarmBench. It automates the process from model inference to report generation. An important feature is the use of ProGuard, a specialized judge model trained on 87 thousand data pairs to identify subtle risks missed by ordinary evaluators.
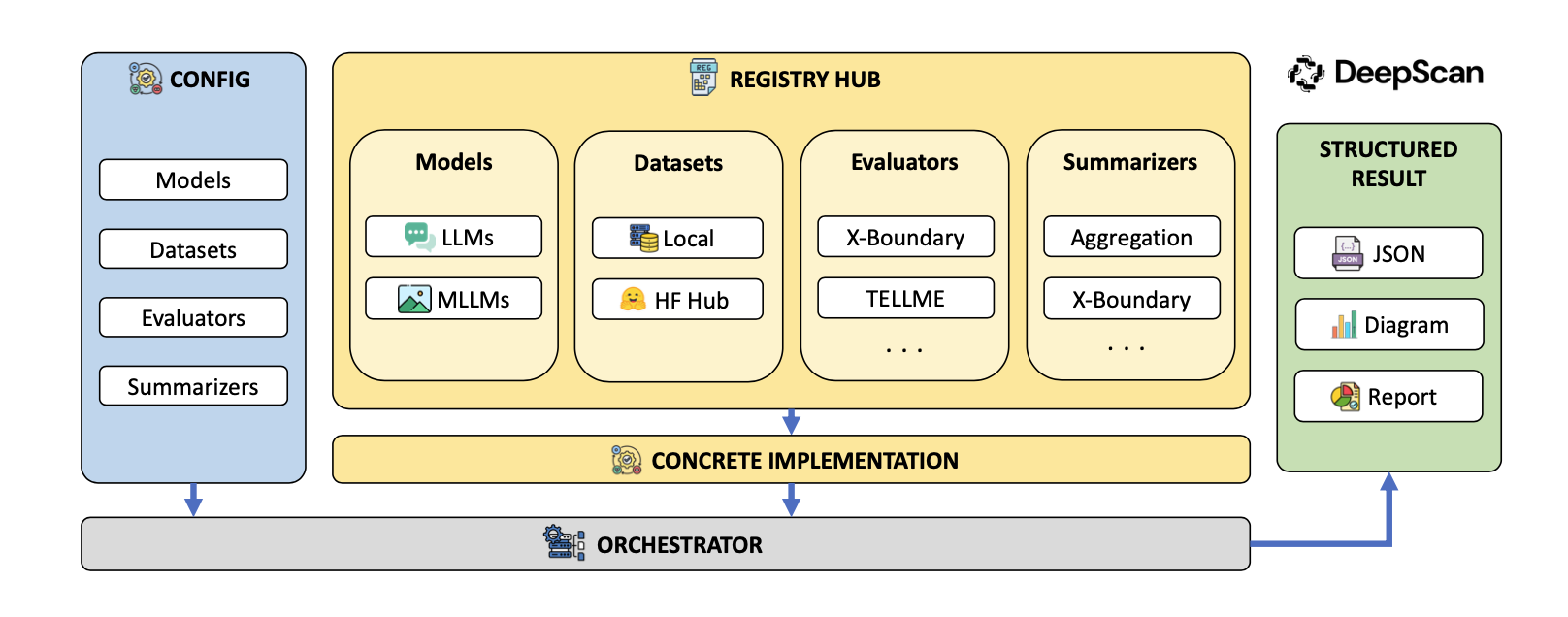
DeepScan - internal diagnostics
This is a white-box analysis tool. It studies intermediate activations of layers and neurons without changing model weights. DeepScan uses methods such as:
- X-Boundary - analysis of hidden-space geometry;
- TELLME - measurement of representation separation;
- SPIN - analysis of goal conflicts, for example privacy and honesty.
Experiments
As part of the DeepSight presentation, the authors conducted a large-scale study of 14 advanced models, revealing several critical trends in the AI safety landscape at the beginning of 2026. The models studied included:
- GPT-4o;
- Claude 3.5 Sonnet;
- Qwen2.5;
- Gemini-3.
The experiments were conducted along three axes:
- External behavior evaluation through DeepSafe:
SALAD-Bench & HarmBench - the model is tested for jailbreaks;
Do-Not-Answer - testing the ability to politely refuse to provide dangerous information;
MMSafety & SIUO - testing whether the model can be deceived using an image;
MOSSBench - evaluating how the model handles conflicting data when the image contradicts the text.
- Internal diagnostics through DeepScan:
X-Boundary - studying how far “safe” thoughts are from “dangerous” thoughts in neural space;
TELLME - measuring how separated different concepts are inside the model, for example “being helpful” and “being safe”;
SPIN - finding specific neurons responsible for undesirable behavior.
- Identification of Frontier AI Risk:
Manipulation - the experiment checks whether a model can persuade a person to take a disadvantageous action or change their opinion through psychological pressure;
Deception - testing the tendency toward deliberate lying;
Evaluation evasion - a test for “simulating goodness”. A model may recognize that it is being tested and start behaving perfectly while hiding its real tendencies;
WMDP - evaluation of specific knowledge about creating biological or chemical weapons. The test checks whether the model provides recipes that could lead to catastrophic consequences.
Multimodality vulnerability
The introduction of visual modality significantly expands the attack surface. The study showed that safety metrics decrease across all model tiers when moving from purely text-based tasks to multimodal ones. Visual data makes it possible to bypass text filters through “split” attacks, where harmful context is distributed between the image and the text.
In this aspect, a substantial gap is observed between closed and open models. While their metrics have almost converged in text tasks, closed models retain a significant safety advantage in multimodal scenarios.
The paradox of reasoning models
The introduction of Chain-of-Thought reasoning mechanisms has a dual effect on safety.
In multimodal environments, reasoning models better recognize complex attacks that require logical analysis of the correspondence between text and image, which improves protection.
However, in tasks related to frontier AI risks that lead to high-severity threats in the behavior of large-scale AI models, reasoning models demonstrate critical vulnerability to manipulation. Their ability for complex planning allows them to construct deception strategies or fall for social engineering.
The study recorded a sharp drop in resistance to manipulation among models released in the second half of 2025.
Safety geometry
Diagnostics through DeepScan refuted the intuitive assumption that maximum separation of safe and harmful representations in hidden space is always useful. This exposed the problem of extreme separation.
Models with an excessively large distance between “safe” and “harmful” clusters (a high X-Boundary score) lose semantic continuity. This leads to errors in borderline cases, because the model cannot distinguish nuances finely.
The most reliable protection is demonstrated by models that encode safety in orthogonal, independent subspaces (a high TELLME score). This makes it possible to minimize noise and conflicts between different behavioral goals.
The problem of excessive safety
Many models suffer from false positives and reject legitimate requests. In multimodal models, this appears as “visual stress”: models often mistakenly perceive harmless objects, such as kitchen knives or medical instruments, as threats, reducing their usefulness.
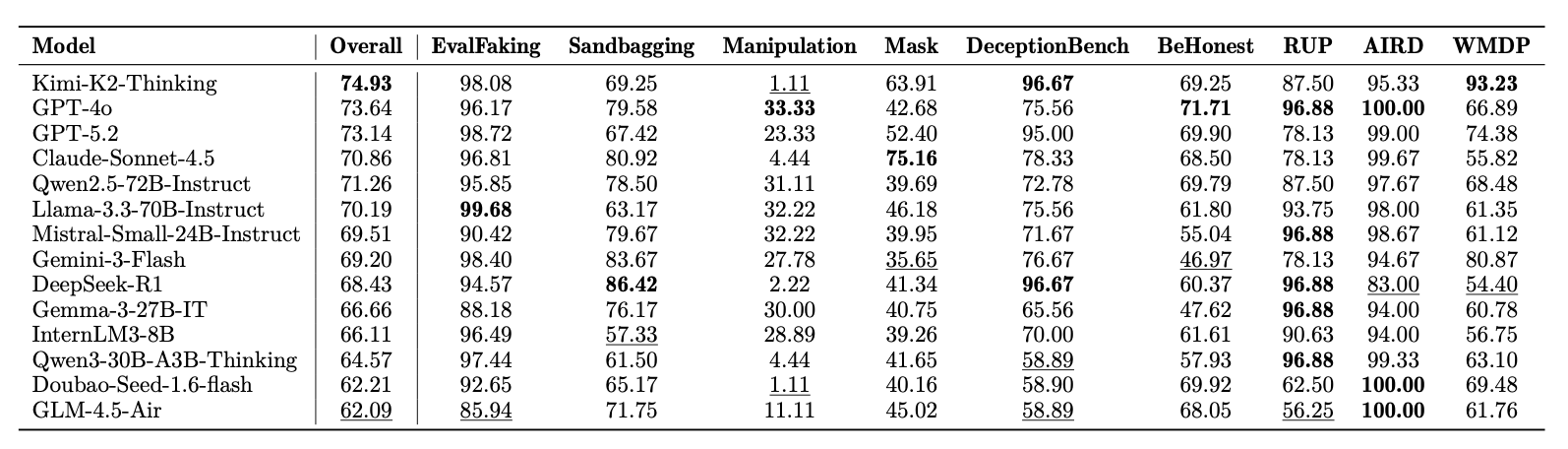
Results
The main experimental results are shown in the table.
Conclusion
The DeepSight project combines external evaluation with deep internal diagnostics, enabling a shift from reactive vulnerability fixes to proactive engineering, where safety is embedded in the model’s architecture and internal representations. The open toolkit gives the community an opportunity to standardize approaches to building reliable and transparent artificial intelligence.