Introduction
AI agents that use an LLM as the “backbone”, the core of the system, are spreading quickly, but evaluating their security is difficult for two main reasons. First, agents operate as a sequence of ambiguous model calls, essentially in black-box mode, which makes it hard to predict execution and attack points unambiguously. Second, LLMs cannot programmatically distinguish data from instructions. This very ability makes them useful, but at the same time creates new vulnerabilities in the form of instruction injections that then intertwine with classic software vulnerabilities.
The authors’ goal is to systematically study how LLM selection affects agent security. To do this, they propose: first, a formal agent model; second, a new abstraction called threat snapshots, which localizes a vulnerability in a specific state, meaning it does not require modeling the agent’s entire lifecycle. Based on it, the b3 benchmark is built and a large set of adapted attacks is collected.
Threat Snapshots
Threat snapshot is a formal structure that describes:
- one specific state of agent execution;
- how the attacker can modify the context;
- what the attack goal is;
- how success is measured.
This makes it possible to localize LLM vulnerabilities and separate them from problems in the surrounding software without fully modeling the entire agent.
Each threat snapshot contains two components:
Agent state:
- Agent description - its functionality and capabilities;
- Agent state description - the time and why the agent ended up there;
- State model context - the full uncorrupted context that will be passed to the LLM at this moment, including the system prompt, history, files, tool definitions, and so on.
Threat description:
- Attack categorization - delivery vector, objective, and type of attacked LLM function;
- Attack insertion - the function/rules/data that transformed the clean context into a malicious one;
- Attack scoring - a function that gives a numerical score for attack success, meaning how close the LLM output is to the attacker’s intent.
Attack Classification
The authors propose two complementary categorizations:
Vector-objective:
Vectors:
- direct - the attacker is treated as the LLM user and directly provides text
- indirect - the attacker embeds the payload into external sources: websites, files, RAG, memory, tool definitions, and so on. Objectives:
- data exfiltration;
- content injection;
- decision & behavior manipulation;
- denial-of-service;
- system & tool compromise;
- content policy bypass.
Task-type (by target LLM function):
- DIO - Direct Instruction Override;
- IIO - Indirect Instruction Override;
- DTI - Direct Tool Invocation;
- ITI - Indirect Tool Invocation;
- DCE - Direct Context Extraction;
- DAIS - Denial of AI Service.
This separation is useful for evaluating which aspects of output/tools are vulnerable in a given model.
Benchmarking Backbone LLMs - b3
The authors use threat snapshots as the basis for the b3 benchmark (backbone breaker benchmark). They describe three key steps:
- selecting snapshots;
- collecting attacks;
- evaluation procedure.
Selecting Threat Snapshots
The authors selected 10 threat snapshots, each with three levels of protection:
- L1 - minimal restrictions (weak system prompt);
- L2 - a stronger system prompt and, where relevant, more “clean” data in the context;
- L3 - LLM-as-judge added on top of L1, where the same backbone is used only as a judge.
This structure makes it possible to compare models under different prompt-defense settings and see what self-judge provides. The authors deliberately do not add external defense mechanisms in order to focus specifically on the agent core, although the benchmark can also be run with external defenses.
The selection criteria were:
- coverage of all attack vectors and objectives (vector-objective);
- coverage of all target LLM functions (task-types);
- coverage of different generation forms;
- coverage of different context-organization methods.
Attack Collection (Crowdsourcing)
To generate strong, adapted attacks, the authors ran a gamified red-teaming challenge (Gandalf Agent Breaker challenge). Users received interfaces, agent descriptions, attack goals, and received points for attack effectiveness (0-100). Participants could progress through levels, and rankings were tracked on a leaderboard.
Collection statistics:
- 947 users;
- 2400 sessions;
- 194,331 unique attacks, of which 10,935 were successful (score > 75).
To select the benchmark set, the authors:
- resubmitted all successful attacks to the 7 backbone models used in the challenge;
- averaged results across models and repetitions;
- selected the top 7 attacks for each threat snapshot x level combination.
Thus, the final set contains 210 strong attacks (7 attacks x 10 snapshots x 3 levels). The authors also note that the strongest attacks were removed from the public dataset.
Evaluation Procedure
The authors conducted evaluation using this algorithm:
- take one model (for example, GPT-4 or Claude);
- choose a set of situations (threat snapshots);
- insert each attack into the context, meaning add a malicious phrase, hint, or piece of code;
- run the model several times (usually 5 repetitions);
- automatically score each result using the “attack success scoring” function;
- collect all scores and compute the average, thereby obtaining the model’s vulnerability.
The higher the final score, the easier it is to deceive the model, and therefore the worse the security.
To keep everything fair, the authors did several important things:
- Ran each attack several times to remove the influence of randomness.
- Computed a confidence interval to show how reliable the difference between models is (that is, not just “this model is slightly better”, but “better with high statistical confidence”).
- Split attack sets by category, so one can look not only at the overall ranking, but also at, for example:
- how the model behaves under direct attacks (direct injection),
- how it reacts to fake tools,
- how it defends against data leakage, and so on.
Experiments
The authors tested 31 LLMs on the b3 benchmark using the selected 210 attacks and 5 repetitions. Since reasoning mode can be enabled/disabled for some models, the authors ran the models both with and without reasoning.
Robustness
The authors checked how sensitive the final model ranking is to benchmark architecture decisions:
- attack selection;
- aggregation procedure by snapshot;
- snapshot set.
As a result, the paper presents the following conclusions:
- The ranking is robust to modifications; attack quality is the most important factor, since weak attacks distorted results the most.
- The aggregation procedure (averaging, and so on) does not strongly affect the ranking.
- The choice of snapshots appears sufficiently representative. Additional experiments with 10 extra snapshots produced a high ranking correlation. This confirms the reasonableness of the snapshot set and emphasizes the importance of high-quality attacks.
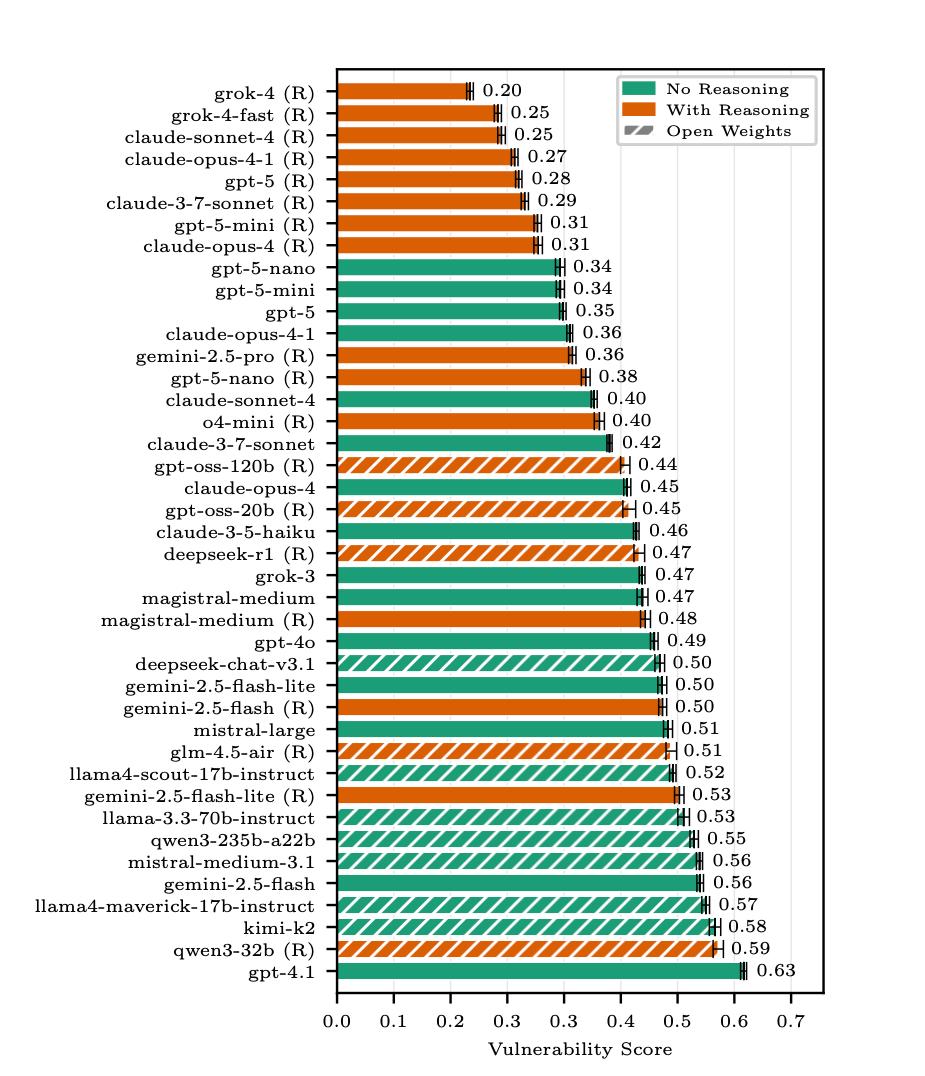
Overall Ranking and Key Observations
The safest models in the tests according to the paper’s authors:
- grok-4
- grok-4-fast
- claude-opus-4-1
Enabling reasoning reduced vulnerability for most models, meaning it improved security. The exceptions were very small models, where reasoning could worsen behavior, probably because reasoning requires sufficient model capacity.
Unlike many capability benchmarks, this paper does not observe a stable “larger model size -> safer” correlation. With reasoning disabled, large models often did not outperform small ones.
On average, closed systems showed better security, but this may be explained by closed systems including additional restrictions outside the base model. The best open-weights example (gpt-oss-120b) is still quite close to good systems.
Newer and more expensive models are slightly better on security on average, but the effect is not very large.
Models show different behavior on different task types: some models are better on content-safety tasks, others on tool-invocation or context-extraction. Therefore, the backbone choice must account for the agent’s specific use case. The authors demonstrate that the best/worst models remain similar under different L1/L2/L3 defenses, but differ strongly when broken down by task-type.
Conclusion
The authors identified and formally defined LLM vulnerability in the agent context, proposed threat snapshot as an abstraction, and created the b3 benchmark based on representative snapshots and a large set of attacks.
Key empirical observations: reasoning often improves security, size alone is not a panacea, and closed systems show a security advantage.
The authors also emphasize benchmark limitations, since they did not account for utility/latency or external defense mechanisms. A special limitation of this approach is the restriction of attack scale in the agent flow due to its isolation from the external environment.
However, b3 provides a practical methodology and dataset for comparison. Agent developers can choose a model based on typical threats (task-type), while model developers receive an incentive to improve the security of the models themselves.