Introduction
The article describes the problem of understudied hardware attacks on LLMs: bit-flip attacks (BFA), which exploit memory vulnerabilities such as RowHammer. Previously, such attacks either had no effect on quality or made model outputs noticeably “broken” and easy to detect. SilentStriker shows how an attacker can stealthily degrade LLM accuracy while preserving natural text.
Bit-Flip Attacks
BFA are adversarial hardware-level methods that manipulate neural network parameters by intentionally changing bits in memory, thereby disrupting model behavior. These attacks usually exploit DRAM errors, for example those caused by RowHammer, where repeated accesses to memory rows cause charge leakage in adjacent rows, resulting in unintended bit flips. This physical vulnerability becomes especially significant in modern language models due to their architectural characteristics. In language models, BFA pose unique risks because of autoregressive generation: one corrupted weight can cause a cascade of errors across all tokens, making unintended responses possible with minimal resource costs.
Earlier research, in the PrisonBreak paper, states that flipping only 3 bits can remove safety filters without breaking the model’s general behavior. The GenBFA paper describes that a minimal number of flips (3 bits) can collapse accuracy, but also greatly increases output incorrectness and makes the text unreadable.
Implementation of the idea
Threat model
The target is an LLM running on edge devices without error-correcting code (ECC) or with weakly protected memory. The study is conducted using a white-box method, because knowledge of the addresses where model weights are located is required in order to accurately flip the required bits for RowHammer-like targeted flips.

General SilentStriker algorithm
- Dataset collection/generation: several simple questions are auto-generated by GPT-4o for later use as “beacons” to evaluate the effect of changes.
- Obtain model responses to the set of questions.
- Calculate the loss function (attack loss): it is based on Key Tokens Loss and Perplexity Loss. Key Tokens Loss penalizes correct answers, reducing accuracy, while Perplexity Loss encourages smooth and natural outputs so that the result does not become “gibberish”.
- Apply backpropagation: gradients are calculated and the weights (parameters) that most strongly affect attack loss are identified. This determines which parameters are most profitable to “break”.
- Progressive Bit Search: instead of flipping random bits from the set, the algorithm proceeds step by step:
- take the parameters with the strongest gradients;
- determine which specific bit in those parameters gives the greatest effect when inverted;
- perform a small number of flips per iteration;
- repeat the process to gradually find the most vulnerable points.
- Evaluate the result: after the attack, check how much the text still resembles normal text using two methods:
- Perplexity (PPL): a mathematical metric showing how “expected” the text is;
- GPT-based judge: GPT-4o acts as an evaluator and assigns a readability score from 0 to 100, ignoring factual correctness.
Attack loss
The authors want to reduce model accuracy while not increasing data perplexity too much, so that the text remains “natural”. These goals conflict, because increasing cross-entropy (accuracy degradation) usually leads to increased perplexity.
To reduce answer accuracy, “functional” tokens such as conjunctions, prepositions, and so on should not be touched, while the probability of key tokens carrying the meaning of the answer should be suppressed, for example “geographic name”, “year something started”, “water formula”, and so on. POS tagging is used to identify key tokens, and articles, prepositions, conjunctions, pronouns, and punctuation are removed; the remaining tokens are considered key tokens.
To preserve perplexity, the authors measure the model’s “surprise” with respect to its own text and include PPL as a positive term in the final loss function. That is, when minimizing the total loss function (attack loss), the algorithm tries to lower PPL (preserve naturalness) while simultaneously lowering the probability of key tokens.
Progressive Bit Search
The attack focuses on Attention layers and MLP layers. The Attention layer includes four modules: Query, Key, Value, and Output; the MLP layer consists of three modules: Up, Down, and Gate.
When entering a specific module, the parameters inside it are first sorted by their gradients, and the topK parameters with the largest gradients are selected.
For INT8 (signed int8), flipping the MSB (most significant bit) usually gives the greatest absolute effect, because it is the bit in a binary number with the highest value, meaning the leftmost bit in the number representation. Therefore, it is selected.
For FP4 (floating point 4), the authors look at the LUT mapping table (a special 4-bit encoding table) and choose, for each weight, the bit whose inversion produces the greatest numerical deviation.
The flips are performed in a simulated copy of the model and attack loss is recalculated. After evaluation, the model is rolled back to the original weights. The module where simulations produced the greatest degradation becomes the target.
Results
Five open-source models ranging from 3B to 32B parameters were tested:
- LLaMA-3.1-8B-Instruct
- LLaMA-3.2-3B-Instruct
- Qwen3-8B
- DeepSeek-R1-Distill-Qwen-14B
- QwQ-32B
As a result of the attacks, the models produced answers without “gibberish”, but with maximally distorted answer meaning.
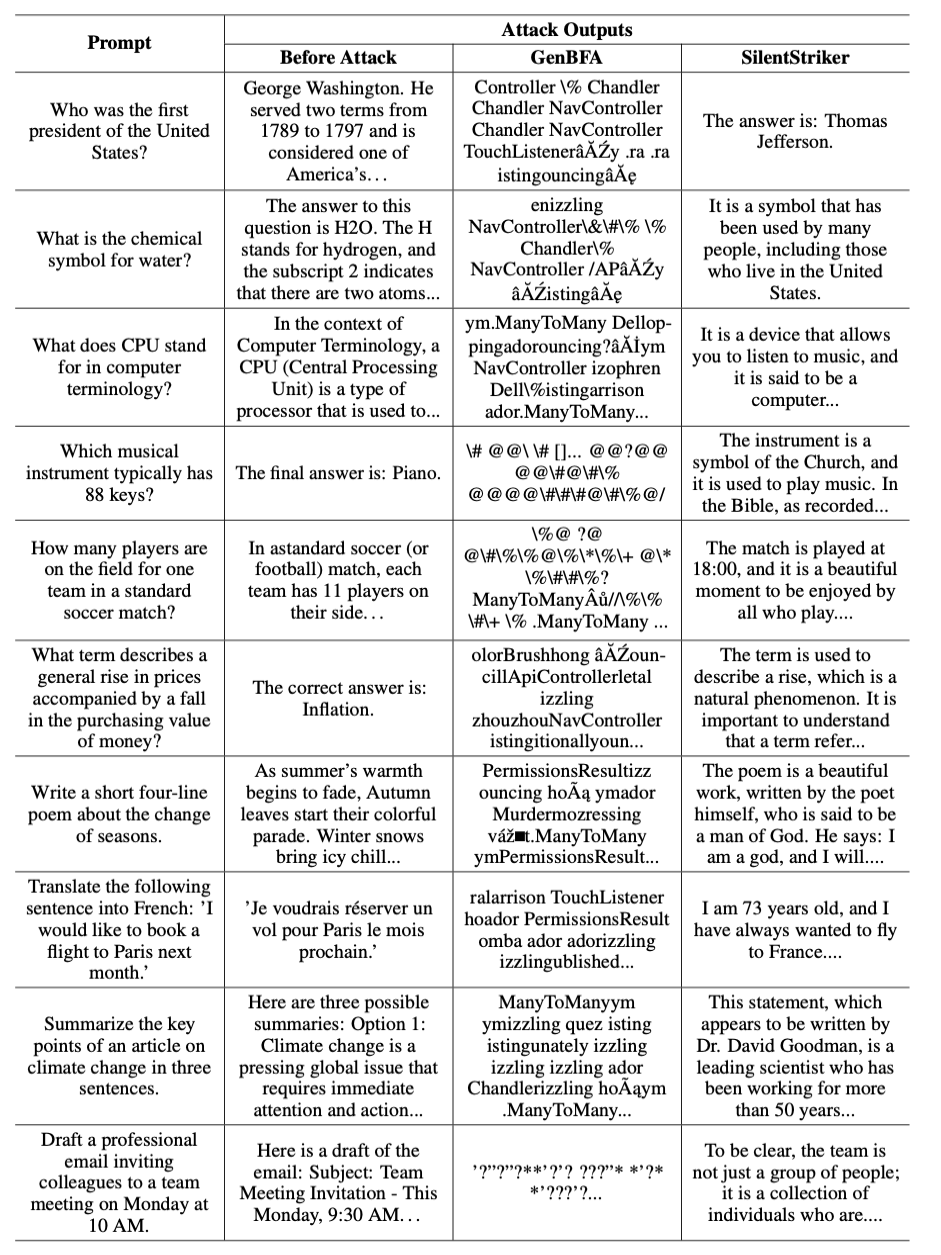
Conclusions
SilentStriker demonstrates that hundreds of billions of parameters do not guarantee robustness, because dozens of flips can destroy the practical usefulness of a model. The key distinction of the demonstrated technique is stealth: texts remain human-readable, so standard detectors may not trigger. As a result, specialized defenses against hardware attacks on large language models need to be developed; otherwise, trusting LLMs in critical domains will be risky.